
VOL90: Scaling PostgreSQL to Power 800 million ChatGPT Users
شركة OpenAI بقالهم سنين معتمدين على PostgreSQL كواحد من أهم الـ Data Systems اللي شغالة في الخلفية وبتشغّل منتجات أساسية جدًا زي ChatGPT و OpenAI API.

لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸 🇸🇩
أهلًا وسهلا بكم في العدد التسعين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هتساعدك على مواكبة أحدث تطورات عالم البرمجة بمواضيع جديدة كل أسبوع، هتلاقى كمان محتوى عملي بيشمل أفضل الممارسات، ونصائح مفيدة، وترشيحات لمقالات مختارة من اقرأ-تِك.
🌟 مواضيع النشرة لهذا الأسبوع 🌟
Scaling PostgreSQL to Power 800 million ChatGPT Users 🚀
OpenClaw: The AI that actually does things 🤖
Layered Architecture 🏛️

Scaling PostgreSQL to Power 800 million ChatGPT Users 🚀
شركة OpenAI بقالهم سنين معتمدين على PostgreSQL كواحد من أهم الـ Data Systems اللي شغالة في الخلفية وبتشغّل منتجات أساسية جدًا زي ChatGPT و OpenAI API. ومع النمو السريع جدًا في عدد المستخدمين، الضغط على قواعد البيانات بيزداد بشكل Exponential. وخلال السنة اللي فاتت بس، الحمل على PostgreSQL زاد أكتر من 10 أضعاف، ومازال بيزيد بسرعة.
وفي خلال رحلتهم وهم بيطوروا الـ production infrastructure علشان تستحمل النمو ده، اكتشفوا حاجة مهمة:
وهي إن PostgreSQL يقدر يـ (scale) ويشيل workloads ضخمة جدًا من النوع الـ read-heavy أكتر بكتير ما ناس كتير كانت متخيلة.
النظام ده (اللي أصله اتعمل على إيد فريق علماء في University of California, Berkeley) مكنهم إنهم يخدموا traffic عالمي وضخم باستخدام single primary Azure PostgreSQL flexible server instance واحدة، ومعاها تقريبًا 50 read replicas متوزعين على أكتر من region حوالين العالم.
في رحلتنا انهاردة هنشوف مع بعض قصتهم وإزاي قدروا يعملوا scale لـ PostgreSQL في OpenAI عشان يخدم ملايين الـ queries في الثانية (QPS) لـ 800 مليون مستخدم، عن طريق optimizations دقيقة وهندسة قوية. وكمان هنشوف أهم الدروس اللي اللي نستفاد بيها في الرحلة دي.
Challenges in The Initial Design
بعد إطلاق ChatGPT، حجم الـ traffic زاد بشكل غير مسبوق. وعشان يواكبوا ده، اشتغلوا بسرعة على optimizations كبيرة على مستوى الـ application وعلى مستوى PostgreSQL نفسه، وكبروا حجم الـ instance (scale up)، وكمان زودوا عدد الـ read replicas (scale out).
الـ architecture دي قدرت انها تخدمهم كويس لفترة طويلة، ولسه مع التحسينات المستمرة بتديهم مساحة للنمو كويسة جدًا قدّام.
وقد ما الموضوع ممكن يبان غريب لكتير من الناس وإن single-primary architecture تقدر تشيل scale بحجم OpenAI، بس الحقيقة إن تطبيق الكلام ده عمليًا مش سهل. وفريق المهندسين في OpenAI شافوا مشاكل كتير و Incidents بسبب الـ overload في Postgres، وغالبًا السيناريو بيبقى شبه بعضه:
مشكلة في إن الـ upstream تعمل spike مفاجئ في load على الـ database
الـ cache layer تقع فيحصل cache misses على نطاق واسع وبالتالي الـ load يزيد على الـ database
الـ expensive multi-way joins تستهلك CPU
أو write storm بسبب feature جديدة نزلت

ومع زيادة استهلاك الموارد، بنلاقي ان الـ latency بتعلى، الـ requests تبدأ في الـ timeout والـ retries تزود الحمل أكتر، وبعدين ندخل في cycle ممكن تبوظ ChatGPT والـ API بالكامل.
Challenges With Write-Heavy Traffic
زي ما قولنا إن PostgreSQL ممتاز جدًا في الـ read-heavy workloads، ولكن ده معناه إن لسه فيه تحديات في الـ write-heavy workload. والسبب الأساسي هنا هو الـ MVCC أو الـ (multi-version concurrency control).
في PostgreSQL، أي update بيحصل حتى لو على field واحد، بيعمل نسخة جديدة من الـ row كله. ومع ضغط writes عالي، ده بيعمل:
Write Amplification
في PostgreSQL، أي UPDATE—event لو على column واحد—ما بيعدّلوش الـ row في مكانه.
بدل كده، النظام بيكتب نسخة جديدة كاملة من الـ row ويخلّي القديمة موجودة.
ده معناه إن: عملية الـ write من التطبيق بتتحول لعدة writes على مستوى الـ table، الـ indexes، والـ WAL فالـ write cost الفعلي أعلى بكتير من اللي ظاهر في الكود، وده اللي بنسميه write amplification.
Read Amplification
بسبب الـ MVCC، النسخ القديمة من الـ rows (dead tuples) بتفضل موجودة لحد ما تتشال.
لما query تعمل SELECT: بنلاقي إن PostgreSQL ممكن يمرّ على أكتر من version للـ row ويستبعد النسخ القديمة لحد ما يوصل للـ version الصح
فـ read واحدة منطقيًا، بتتحول لعمليات قراءة أكتر على مستوى الـ storage و CPU وده اسمه read amplification.
Table & Index Bloat
مع كثرة الـ updates: الـ dead tuples بتتراكم والـ indexes بتفضل شايلة references لبيانات اتحذفت والمساحة ما بترجعش بسهولة للـ OS
والنتيجة:
حجم الـ tables والـ indexes يكبر
الـ queries بتبقى أبطأ
والـ disk I/O بيزيد
Index Maintenance Overhead
كل INSERT أو UPDATE:
بيحتاج تحديث لكل index مرتبط بالـ row
ومع MVCC، الـ indexes نفسها بتدخل في دايرة versions قديمة وجديدة
ولو الـ table عليه أكتر من index:
فتكلفة الـ write بتزيد بشكل Linear مع عدد الـ indexes
والـ CPU والـ disk usage بيعلى
والـ autovacuum يبقى عليه شغل أكتر
Autovacuum Tuning Complexity
الـ autovacuum هو المسؤول عن التنضيف بمعنى تاني:
إزالة الـ dead tuples
تقليل الـ bloat
الحفاظ على أداء الـ DB
ولكن لو كان aggressive بزيادة → بيزاحم الـ queries ولو كان conservative بزيادة → الـ bloat والـ latency بيعلوا
عشان كده autovacuum tuning واحد من أعقد أجزاء تشغيل PostgreSQL في الـ production.
Scaling PostgreSQL to Millions of QPS
عشان يقللوا الضغط على الـ writes، بدأوا يرحلوا الـ workloads اللي ينفع تتقسم (shardable) واللي فيها writes كتير لأنظمة sharded زي Azure Cosmos DB، وكمان عدلوا على الـ application logic عشان يقللوا أي writes ملهاش لازمة.
كمان، منعوا إضافة أي tables جديدة على PostgreSQL الحالي. وأي workload جديد بقى default يروح على الأنظمة الـ sharded.
ورغم كل التطوير ده، PostgreSQL لسه unsharded، وفيه single primary مسؤولة عن كل الـ writes. والسبب هو إن الـ sharding للـ workloads الحالية معقد جدًا، وعايز تغييرات كتيرة في مئات الـ endpoints، وممكن ياخد شهور أو سنين.
وبما إن معظم الشغل كان عندهم read-heavy، ومع شوية optimizations قوية، فالتصميم الحالي لسه مديلهم مساحة كافية للنمو. فكل بساطة الـ sharding لـ PostgreSQL ممكن يحصل في المستقبل، بس مكنش أولوية ليهم دلوقتي.
Reducing Load on The Primary
المشكلة:
الـ Single-primary لوحده بكل تأكيد مش هيعرف يعمل scale للـ writes. وأي spike في الـ writes ممكن يوقع الـ primary وبالتالي يأثر على ChatGPT والـ API.
فالحل:
بدوا يقللوا الحمل على الـ primary لأقصى درجة ممكنة وده من خلال الآتي:
عمليات القراءة - reads بتروح على الـ replicas
الـ reads اللي جوه write transactions بيخلوها optimized لإنها كده كده لازم تعدي على الـ Primary
والـ write-heavy shardable workloads اتنقلت لـ CosmosDB زي ما وضحنا
كمان صلحوا bugs كانت بتعمل redundant writes علشان يقللوا عمليات الكتابة قدر المستطاع
استخدموا الـ lazy writes ومن اشهر الـ techniques لحاجة زي كده (batching, debouncing, write-behind-cache)
وعملوا strict rate limits أثناء عمليات الـ backfilling لبعض الـ fields اذا دعت الحاجة لده عشان يقللوا الضغط على الـ writes.
Query Optimization
المشكلة:
الـ Queries التقيلة كانت بتاكل من الـ CPU جامد، ومع وجود الـ spikesالخدمة كانت بتبطّأ.

OpenClaw: The AI that actually does things 🤖

خلال الشهر اللي فات انتشر مشروع بين المبرمجين اسمه clawdbot ( اتعمله rebrand ل OpenClaw)واتعمله Stars علي Github بشكل غير طبيعي زي ما أنتو شايفين 🤷♀️
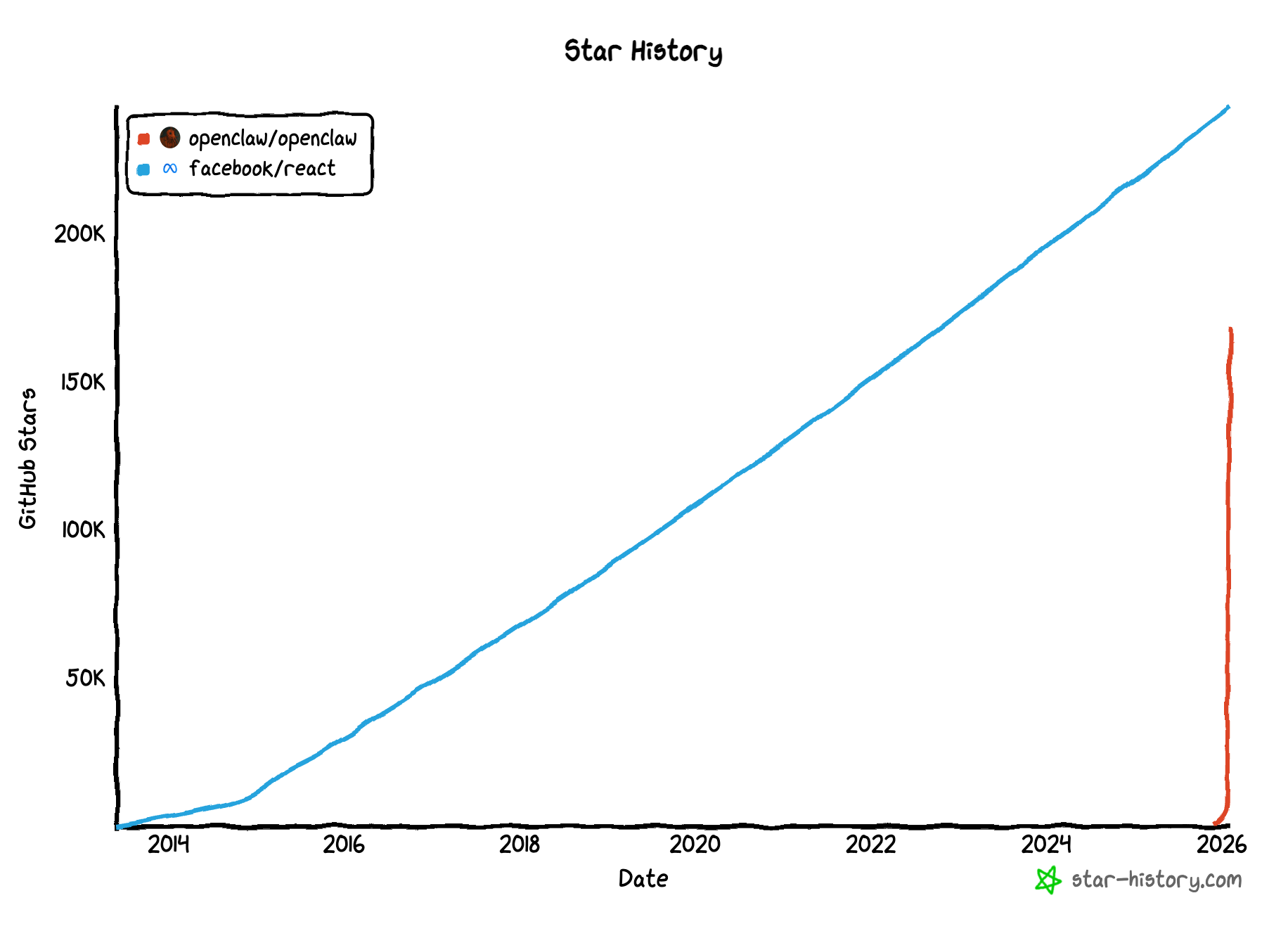
Open Claw هو مشروع مفتوح المصدر عشان تبني Personal Assistant أو AI Agent بيشتغل على جهازك أو السيرفرز بتاعتك، وتقدر توصله بمنصات محادثة مختلفة وتعمله prompting من عليها زي(WhatsApp, Telegram, Slack, Discord, Signal, iMessage، وغيرها).
فهو بس مش مجرد chatbot بتقدر تكلمه من الواتساب ولكن تقدر تديله مهام وأوامر ينفذها علي السيرفر أو الكمبيوتر بتاعك!
المشروع سهل الاستخدام جدًا ودا اللي شجع ناس كتير تستخدمه وتعدل فيه وتزودله Skills مختلفة. والمشروع بيتقسم لجزئين أساسيين:
AI Gateway
وهي عبارة عن Interface بتشغل الـ Assistant وتربطه بالـ models (GPT/Claude) وأي نظام تشغيل.
Agents & Skills
الـ Agent وهو اللي بيقدر ينفذ الأوامر.
الـ Skills وهي عبارة عن (Plugins) اللي بتوسّع مهام الوكيل.
مثال: Skill لإدارة ال Calendar أولإرسال رسائل على التليجرام .
ولكن قبل الاستخدام لازم نلفت نظرك عزيزنا المبرمج لكون عليه ملاحظات أمنية كبيرة لأنه عند صلاحيات وصول لأجزاء كبيرة من الSystem وأهمها ال Files Systems وزي ما يقدر ينفذ مهام مفيدة ممكن مع أي Skill فيها كود غير واضح أو من مصدر مجهول تكون خطر كبير علي بياناتك ونظامك ككل. عشان كدا لازم تقيمه من الناحية الأمنية كويس قبل استخدامه والأفضل إنك مستخدموش علي جهازك الرئيسي أو تعزله قدر الإمكان في VM وبدون صلاحيات الوصول لل Host. تقدر كمان تعمله allowlist بال Commands اللي يقدر يستخدمها ويكون مفيهاش خطر وأهم حاجة تراجع ال Skills كويس قبل استخدامها لأن بالفعل تم اكتشاف Skills كثيرة مليئة بال Malware علي ال Marketplace الخاص بالمشروع.
شاركونا تجربتكم معاه إذا استخدمتوه بالفعل بتستخدموه في مهام إيه وايه ال Security Measures اللي خدتوها.
Layered Architecture 🏛️
الـ Layered Architecture طريقة شائعة جدًا بنستخدمها علشان نرتب بيها الكود في أي software system. الفكرة ببساطة إننا بنقسم المشروع بتاعنا لكذا layer، وكل layer بيكون ليه وظيفة محددة، ومش بيكلم غير layer اللي تحته.
الـ layers دي ممكن تكون 1 أو 2 أو 3 ، فعدد الـ Layers مش بيفرق ولكن كلهم بيتبعوا نفس الـ Rule الا وهو ان كل Layer بتعتمد على الـ Layer اللي تحتها.
يعني بكل بساطة بنفصل المسئوليات بحيث كل layer طبقة مسئولة عن حاجة واحدة، وده بيسهّل علينا نشتغل على كل جزء من السيستم بأريحية ومن غير مانكون خايفين إننا نأثر بالسلب على باقي الأجزاء.

مميزات الـ Layered Architecture
في كذا ميزة للـ Layered Architecture:
الـ Code هيبقى أسهل في الفهم: لما كل حاجة تبقى في مكانها، تقدر بسهولة تعرف فين الـ business logic، فين الـ database access، وفين الـ UI.
الـ Testability: تقدر تختبر كل layer لوحده. يعني مثلًا تقدر تعمل unit testing للـ service layer اللي هيكون فيها الـ Business Logic بتاعك من غير ما تكون مرتبط بالـ Database.
الـ Maintainability وقابلية التعديل والتوسع: لو عايز تغيّر طريقة حفظ الداتا، ممكن تشتغل بس في الـ data access layer من غير ما تلمس باقي السيستم وده هيديق ثقة وأنت شغال.
الإنتاجية كـ Team: كل حد ممكن يشتغل على layer معينة في الـ Project من غير ما يأثر على باقي شغل الناس التانية خصوصًا لو بيشتغلوا على Features مختلفة.
أشهر Layers في أي Layered Architecture
الترتيب بيختلف من مشروع للتاني، بس غالبًا هنلاقي أغلب الحاجات دي:
الـ Presentation Layer (أو UI Layer)
ودي اللي بتتعامل مع اليوزر، سواء كانت Web UI أو Mobile أو حتى Command Line. وفي حالة الـ Backend الـ Controller بتمثلنا احنا الـ UI لانها بتـ Represent البيانات للـ Frontend على هيئةJSONأو أي Data Format محددينه.الـ Application Layer / Service Layer
فيها الـ business logic بتاعنا، يعني القواعد اللي السيستم ماشي بيها. وكذلك ممكن تتضمن وجود الـ Domain / Model Layer والـ Entitiesالـ Persistence / Data Access Layer
ودي اللي بتتعامل مع الـ database أو أي data source تاني أو حتىAPIsأو Web Services.
مثال بسيط
لو عندنا system بيحجز مواعيد لدكتور على سبيل المثال:
فالـ UI بياخد من الـ user التاريخ اللي عايز يحجز فيه الميعاد.
الـ Business Layer فيها الـ Logic واللي من خلاله بتشوف لو التاريخ ده الدكتور متاح فيه ولا لأ.
الـ Data Access Layer بتشوف في الـ database المواعيد المحجوزة فعليًا والاتاحية بتاعة الدكتور وبعدين تخزن الميعاد بتاع الحجز لو فيه اتاحة.
ليه الناس بتقول إن Layered Architecture “قديم” أو “مش أفضل اختيار”؟
الـ Layered Architecture فعلاً كان هو الـ default من زمان، خصوصًا في التطبيقات الكبيرة زي اللي كانت بتتبني بالـ Java EE أو .NET، لأنه بسيط وسهل يتفهم. بس مع الوقت، ظهرت مشاكل معينة خلت الناس تدور على بدائل أفضل، زي Clean، Onion، وHexagonal.
طيب إيه مشاكله؟
رغم المميزات اللي قولناها، لكن فيه شوية مشاكل بتبان في الـ real world:
مبدأ الـ Dependency Inversion: في الـ layered architecture، الطبقات اللي فوق (UI مثلاً) بتعتمد بشكل مباشر على اللي تحتها (Services → Repositories → Database). وده بيخلي الـ business logic مربوط بحاجة زي SQL أو حتى ORM، وده بيصعّب التستينج وإعادة الاستخدام الا لو اضطرينا اننا نستعمل في الوقت ده الـ Dependency Inversion. عشان نكسر الاعتمادية دي.


بفضل الله أصبح متاح حالياَ دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship, بنرحب بجميع الشراكات مع المؤسسات والشركات وأصحاب الأعمال لبناء مجتمع عربي يشجع على القراءة والتعلم ومشاركة التجارب والخبرات العملية في هندسة البرمجيات.
دورك كشريك أو راعي هيكون محوري في دعم المحتوى وتوسيع نطاق تأثيره. فانضم لرحلتنا وكن جزءًا من صناعة مستقبل التكنولوجيا في المنطقة 🚀
شركاء النجاح:

تقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 👇

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
