
VOL88: The Invisible Shield - How VPN Works ?
أهلًا وسهلا بكم في العدد الثامن والثمانين من النشرة الأسبوعية لاقرأ-تِك 🚀

لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸🇸🇩
أهلًا وسهلا بكم في العدد الثامن والثمانين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف،نشرتنا تساعدك على مواكبة أحدث تطورات عالم البرمجة بمواضيع جديدة كل أسبوع, هتلاقى كمان محتوى عملي بيشمل أفضل الممارسات، ونصائح مفيدة، وترشيحات مقالات مختارة من اقرأ-تِك.
مواضيع النشرة لهذا الأسبوع:
How VPN Works
How Slack Handles Billions of Tasks in Milliseconds
Idempotency in APIs
How VPN Works
المبرمجين ليهم علاقة غريبة بالـ VPN بنستخدمه بشكل يومي أو شبه يومي بس في نفس الوقت مش عارفين كل تفاصيله لأننا مش بتوع شبكات, النهارده هنتكلم عن أهم الحاجات اللي لازم أي مبرمج يعرفها عن الـ VPN: هو إيه، بيحل مشاكل إيه، بيشتغل إزاي، مميزاته وعيوبه، وإزاي تختار VPN مناسب من غير ما تقع في فخ التسويق .
ما هو ال VPN
VPN اختصار لـ Virtual Private Network، وهو ببساطة طبقة وسيطة بتعمل نفق مشفّر (Encrypted Tunnel) بين جهازك وبين الإنترنت أو شبكة خاصة.

المشكلات التي يحلها ال VPN
الـ VPN لم يظهر أساسًا عشان الخصوصية الشخصية أو فتح المواقع المحجوبة زي ما هو شائع اليوم، بل ظهر كحل تقني لمشكلة واضحة جدًا في بيئة الشركات.
ودا لأن كل شركة بيكون عندها Private Network عليه مواردها وأجهزتها ولما موظف يسافر أو يشتغل من فرع الشركة في مكان تاني مبيقدرش يوصل للشبكة الداخلية من خلال الإنترنت لأن دا اتصال غير آمن. عشان نحل المشكلة دي كان في حل Physical باننا نوصل سلك لجهاز الموظف دا أو بالفرع التاني “طبعًا حل غير منطقي” فالحل بدلً من السلك إننا نعمل Tunnel أو أنبوبة آمنة من خلال الانترنت بين جهاز الموظف والشبكة الداخلية للشركة نمرر فيها البيانات المهمة بتاعتنا ووقتها بيظهر جهاز الموظف كأنه جزء من شبكة الشركة ومن هنا جه الإسم Virtual Private Network
مع الوقت تطور ال VPN وإلي جانب ال Remote Private Network Access أصبحت استخداماته بتشمل:
أداة لزيادة خصوصية تصفحك علي الانترنت
ودا لأن ال Internet Service Provider (ISP) بتاعك بيقدر في الطبيعي يشوف المواقع اللي انت بتزورها وتقدر كمان ال Services اللي انت بتستخدمها تتبع موقعك الجغرافي, ال VPN بيحل المشكلة دي لأنه بيغير ال IP Address بتاعك وبيبان ال VPN Server IP و بالتالي بيكون تتبعك أصعب و ال ISP لا يزال بيشوف مقدار الترافيك اللي بتستخدمه ولكن ميقدرش يعرف تفاصيل أكثر من كدا.
فتح Services مقفولة جغرافيًا
- معظم دول العالم بتفرض قيود على المحتوى اللي تقدر توصله وأنت بداخل البلد فمثلاً متقدرش تفتح Youtube في الصين من غير VPN. ال VPN بيحل المشكلة دي لأنه زي ما قولنا ال ISP مش عارف أصلاً أنت بتزور مواقع ايه وبالتالي ميقدرش يحجب موقع هو مش عارفه.
-كمان Payment Services كتير بتكون محدودة جغرافيًا كوسيلة حماية للخدمات دي من ال International Hacking فلو أنت مبرمج ومحتاج تختبر Integration مع خدمة دفع في بلد تانية فالـ VPN بيديك حرية تختبر الخدمة/المنتج من أكتر من Location.
الأمان على الشبكات العامة
لو شغال في كافيه أو Co-working Space أو في فندق مثلاً علي Public WIFI فبتكون عرضة لهجمات زي Packet Sniffingو Man-in-the-Middle Attacks وعشان كدا ضروري تستخدم VPN خصوصًا لو بتستخدم Credentials/Tokens/SSH
المميزات
تشفير الاتصال، كل ال Traffic بتاعك مع استخدام VPN بيكون Encrypted فلو أنت بتستخدم موقع HTTP و لا يدعم HTTPS فاستعمال VPN خطوة لا غنى عنها.
إخفاء الـ IP الحقيقي
الوصول إلى الشبكات المغلقة Private Networks زي سيرفرات الشركة وغيرها
مرونة في اختبار وتطوير البرامج المختلفة
تقليل المخاطر وقت استخدام الشبكات العامة
العيوب
انخفاض السرعة، دا لأن ال Latencey بتكون أعلى وال Bandwidth أقل, ودا لأن ال VPN بيعمل Wrapping لكل ال Packets ب Headers إضافية وبيشفرها.
الاعتماد على طرف ثالث، وقت ما تعتمد على ال VPN Provider فأنت كل ال Traffic بتاعك بيعدي من على سيرفراته وبالتالي …..
How Slack Handles Billions of Tasks in Milliseconds
المقدمة
لو جينا نبص على Slack هنلاقيها بتستخدم job queue system علشان تنفّذ الـ business logic اللي بياخد وقت كبير ومينفعش يتنفذ جوه الـ web request الطبيعي. والسيستم ده جزء أساسي في البنية التحتية بتاعت Slack، وكمان بيتم استعماله في كل message بتتبعت، وكل push notification، وكل URL unfurl، والتذكيرات، وحساب الفواتير وغيرها كتير من المميزات اللي Slack بتقدمها.
في أغلب الأيام اللي بيكون عليها ضغط كبير، السيستم بيعالج أكتر من 1.4 مليار job، بمعدل بيوصل لـ 33,000 job في الثانية. وده رقم ضخم جدًا ومع ذلك تنفيذ الـ jobs بياخد من ميلي ثانية لحد دقايق أحيانًا.
الـ job queue القديم اللي كانوا بيستخدموه من أول ما Slack بدأت، قدر يمشي معاهم الرحلة دي وهم بيكبروا. وكل ما كانوا بيقابلوا مشاكل في الـ CPU أو الـ memory أو الـ Network، كانوا بيعملوا scaling، لكن الـ Architecture الأساسي للـ System فضل زي ما هو تقريبًا.
من حوالي سنة، حصل عندهم production outage كبيرة بسبب الـ job queue. كان فيه مشكلة في الـ database layer، خلت تنفيذ الـ jobs يبقى بطيء جدًا، وده خلى Redis يوصل لأقصى سعة من الـ memory الممكنة. ولما مابقاش فيه memory فاضية، مقدروش يحطوا jobs جديدة، وبالتالي كل حاجة كانت معتمدة على الـ job queue وقعت.
اللي زوّد الطين بلة إن حتى عملية الـ dequeue كانت محتاجة memory، فكده الموضوع كان بايظ من الناحيتين لا عارفين يزودوا jobs جديدة ولا حتى يعملوا dequeue للـ jobs الموجودة بسبب ان مفيش free memory ، فحتى بعد ما مشكلة الـ database اتحلت، الـ queue فضلت واقفة، واحتاجت تدخل يدوي عشان تشتغل تاني.
الـ incident دي خلتهم يعيدوا تقييم الـ job queue system كله، وبدأوا يخططوا لتغيير كبير في التصميم، لكن من غير ما يوقفوا أي service، أو يعملوا migration ضخم، وكمان يوفروا سبيل لأي تحسينات مستقبلية ممكن يضيفوها بعدين.
Slack’s Initial Job Queue System Design
الـ system design القديم بتاع الـ job queue عند Slack كان ممكن ترسمه بالشكل ده، وغالبًا هيكون مألوف لأي حد اشتغل أو استخدم Redis task queue قبل كده.
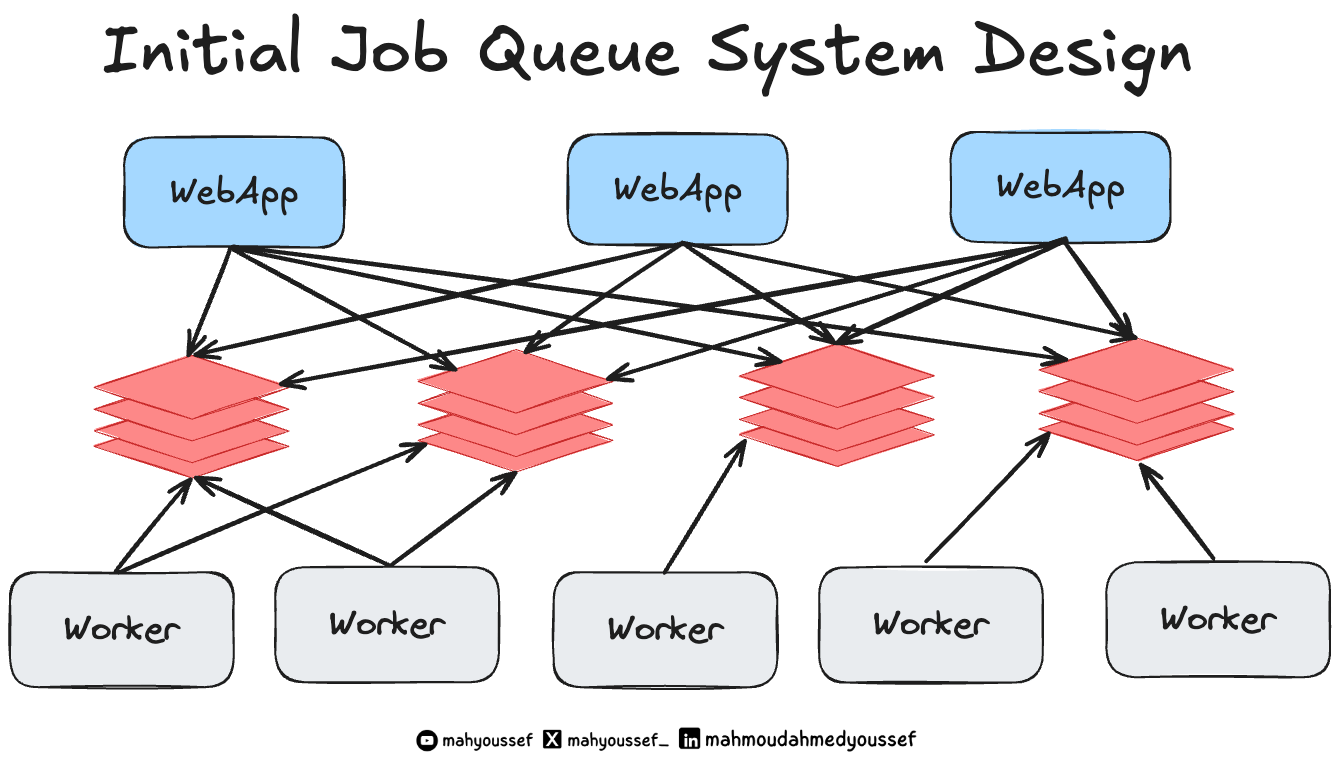
Job’s Lifecycle
لما الـ web app بيعمل enqueue لـ job: أول خطوة بتكون إنه ينشئ identifier (وده unique identifier) مبني على نوع الـ job والـ arguments اللي جاية معاها.
الـ enqueue handler بيختار واحد من Redis hosts: والاختيار بيتم بناءً على استعمال hash من الـ identifier ده وكمان الـ logical queue اللي تخص الـ job دي ، يعني كل job بتروح على Redis معين حسب نوعها ومحتواها.
في Redis، بيستخدموا data structures علشان يعملوا deduplication وبيكون limited شوية: فلو فيه job بنفس الـ ID أصلًا موجودة جوه الـ queue الطلب الجديد بيتلغى. ولو مفيش واحدة زيها الـ job بتضاف للـ queue.
الـ Workers دايمًا بتعمل polling على Redis clusters: في الـ background، بيكون فيه pools من الـ (worker machines) متابعة وبتراقب الـ queues، ومستنية يظهر أي job جديدة عشان تشتغل عليها. أول ما واحدة من الـ workers تلاقي job في queue من اللي هي بتراقبهم:
بتنقلها من pending queue لـ in-flight list (يعني الشغل اللي شغال عليه دلوقتي).
بتبدأ تشغّل (asynchronous task) علشان تنفّذ الـ job دي.
بعد ما الـ task تخلص: الـ worker بيشيل الـ job من قائمة in-flight jobs ولو الـ job فشلت وحصلها (failure) بتتحط في queue خاص بإعادة المحاولة (retry queue). وبيتم إعادة المحاولة عدد معين من المرات، لحد ما يا إما تنجح ، يا إما تتحط في قائمة تانية اسمها permanently failed jobs (اللي بيتم مراجعتها يدويًا علشان يشوفوا هي فشلت ليه، ويحلوها لو محتاجة تدخل بشري).
Architectural Challenges
بعد ما عملوا post-mortem للـ outage اللي حصل، Slack وصلت لاستنتاج واضح:
“الـ scaling بالنظام الحالي مش هينفع، ولازم نشتغل على تغييرات جذرية أكتر.”
طب إيه هي المشاكل والقيود اللي اكتشفوها؟
مبدئيًا كده Redis كان مفيهوش مساحة كفاية، خصوصًا من ناحية الـ memory: فلو عدد الـ jobs اللي بتتعمل enqueue بقى أسرع من الـ dequeue لفترة طويلة، السيستم بيستهلك الذاكرة كلها. ولما الـ memory تخلص، حتى dequeueing ميبقاش ممكن (لأنه هو كمان بيحتاج memory علشان يحرك الـ job لقايمة الـ processing).
الـ Redis connections كانت عاملة complete bipartite graph: كل client (أي system بيعمل enqueue) لازم يكون متصل بـ كل Redis instance. وده معناه إن كل client لازم يعرف كويس كل تفاصيل Redis nodes، ويكون عنده config مظبوط ومحدّث دايمًا.
الـ Job workers ماكانوش يقدروا يعملوا scaling لوحدهم من غير Redis: كل ما بنزود عدد الـ workers بنحط load أكتر على Redis.
الاختيارات اللي كانوا عاملينها قبل كده في الـ Redis data structures كانت مكلفة: علشان نعمل dequeue من الـ queue، كان لازم نعمل عمليات تتناسب مع الـ queue length نفسه. أو بمعنى أبسط (كل ما الـ queue يطول، كل ما بيبقى أصعب إننا نفضيه).وده كان مخلي الأداء يبقى أسوأ مع الوقت.
الـ semantics والـ QoS (quality-of-service) guarantees اللي بتتقدم للـ app والـ platform engineers كانت مش واضحة: فالـ async job processing كان مفروض يكون حاجة أساسية في الـ architecture ، لكن في الواقع، المهندسين كانوا بيترددوا يستخدموه علشان سلوكه مكنش متوقع. فأي تغيير حتى ولو بسيط (زي موضوع deduplication المحدود) كان high-risk جدًا، لإن فيه jobs كتير بتعتمد عليه علشان تشتغل صح.
طب يعملوا إيه؟ إيه الحل؟
كل مشكلة من دول كانت ممكن تروح في كذا اتجاه من الحلول — من مجرد تحسينات بسيطة، لحد عملية الـ Re-Write للسيستم من الصفر. لكن Slack قرروا يركزوا على 3 نقاط رئيسية ممكن تحل المشاكل اللي ليها أولوية:
استبدال Redis بـ durable storage (زي Kafka): علشان يبقى فيه buffer يتحمّل ضغط الـ memory، وميفقدش الـ jobs لو حصل أي overload. وده لإن Kafka يقدر يحتفظ بالبيانات دي بأمان على الـ disk، بدل ما كل حاجة تبقى in-memory.
بناء scheduler جديد خاص بالـ jobs: ده هيساعدهم يقدّموا guarantees أفضل من ناحية QoS. وكمان يقردوا يوفّرا features بأريحية زي مثلًا الـ rate-limiting، والـ prioritization في تنفيذ jobs.
فصل تنفيذ الـ jobs عن Redis تمامًا: كده أصبح بإمكانهم إنهم يعملوا scale للـ job execution من غير ما يضطروا يتعاملوا مع Redis نفسه.
Incremental Change or Full Rewrite
فريق Slack كانوا عارفين إن تنفيذ كل التحسينات اللي خططوا ليها هيحتاج تغييرات كبيرة في الـ web app وفي الـjob queue workers. علشان كده الفريق قرر يركز على أهم المشاكل اللي عنده، وياخد خبرة عملية مع أي جزء جديد من النظام بدل ما يحاول يعمل كل حاجة مرة واحدة.
Idempotency in APIs
عند تصميم واجهات برمجة التطبيقات (APIs)، يُعد مفهوم الـ Idempotency من المفاهيم المُهمة لضمان استقرار الأنظمة و سلامة بياناتها، لا سيما في الأنظمة الموزعة حيث ترتفع احتمالية تكرار الطلبات نتيجة لمشاكل الشبكة Network Failures أو إعادة المحاولة التلقائية Retries.
في هذا المقال سنستكشف مفهوم الـ idempotency، أهميته في تصميم الـ APIs، الآليات المتبعة لتحقيقه و متى يُستخدم.

ما هو الـ Idempotency؟
الـ Idempotency هو مفهوم مُستعار من الرياضيات، و يعني أن تنفيذ عملية مُعينة مرة واحدة أو عدة مرات سيُعطي نفس النتيجة. في سياق الـ APIs هذا يعني أنه يُمكن تنفيذ نفس الطلب Request عدة مرات دون أن يُؤثر ذلك على حالة النظام أو ينتج عنه آثار جانبية غير مرغوب فيها.
// idempotent operation
const result = Math.abs(-5); // النتيجة: 5
const result2 = Math.abs(-5); // النتيجة: 5 (نفس النتيجة)
// non-idempotent operation
let counter = 0;
const increment = () => ++counter;
increment(); // النتيجة: 1
increment(); // النتيجة: 2 (نتيجة مختلفة)
أهمية الـ Idempotency في الـ APIs
أحيانا يفقد العميل تأكيد نجاح العملية بسبب مشاكل الشبكة فيُعيد إرسال الطلب. لذلك يجب أن يتحمل النظام تكرار نفس الطلب دون تكرار التنفيذ.
بعض الأنظمة تعتمد على إعادة المحاولة تلقائيا عند فشل الطلب مؤقتا مما يجعل دعم الـ idempotency ضروريا لتفادي تكرار غير مرغوب فيه.
في العمليات الحساسة كتنفيذ المعاملات المالية قد يؤدي تكرار التنفيذ إلى أخطاء خطيرة إن لم يُراعى مفهوم الـ idempotency.
في الأنظمة الموزعة تكرار الطلبات أمر شائع بسبب الأعطال الجزئية، لذلك يُدعم الـ idempotency موثوقية النظام و سلامة بياناته.

بفضل الله أصبح متاح حالياَ دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship, بنرحب بجميع الشراكات مع المؤسسات والشركات وأصحاب الأعمال لبناء مجتمع عربي يشجع على القراءة والتعلم ومشاركة التجارب والخبرات العملية في هندسة البرمجيات.
دورك كشريك أو راعي هيكون محوري في دعم المحتوى وتوسيع نطاق تأثيره. فانضم لرحلتنا وكن جزءًا من صناعة مستقبل التكنولوجيا في المنطقة 🚀
تقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 👇

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
