
VOL69: Credit & Debit Cards Explained
أهلًا وسهلا بكم في العدد التاسع والستين من النشرة الأسبوعية لاقرأ-تِك 🚀


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد التاسع والستين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية، من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة، ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

Credit & Debit Cards Explained
How Discord Stores Trillions of Messages
Concurrency Building Blocks (Threads)
ACID Properties in DBMS
الإصدار الأول من مدونات فطين في تصميم النظم
Credit & Debit Cards Explained
بطاقات الدفع جزء من حياتنا اليومية ومع الوقت بيزيد احتياجنا لفهمها كمبرمجين لأنها من أكثر وسائل الدفع انتشارًا وأغلب التطبيقات بتدعمها لتسهيل عملية الدفع لمستخدميها, ورقة وقلم وتعالوا نعرف كل التفاصيل عن الجانب التقني منها.
ما هي بطاقة الدفع؟
بطاقة الدفع هي وسيلة تقنية بحتة تساعد حاملها إنه يدفع بيها بدلاً من حمل الفلوس بشكل فعلي سواء Debit/Credit في أكثر من استخدام:
سحب/إيداع الأموال باستخدام ATM
في المحل وقت الشراء مع جهاز Terminal بيقرأ تفاصيل البطاقة باستخدام الـ Chip أو الـ Magnetic strip.
أو بإدخال بياناتها أثناء الدفع على الموقع في خطوة ال Checkout
بيهمنا كمبرمجين بيانات البطاقة لأنها بتساعدنا على التعرف على نوع البطاقة وصلاحيتها والبنك المصدر ليها وشبكة البطاقات اللي هتقدر تعملها processing
مكونات البطاقة

رقم البطاقة (PAN: Primary Account Number)
هو رقم مكون عادة من 16 رقم( بعض شبكات البطاقات تجعله أقصر من 16 ) وبنستخدمه لتعريف البطاقة عند إجراء عمليات الشراء أو السحب أو الدفع عبر الإنترنت, الرقم دا بينقسم لعدة أجزاء
الرقم الأول: بيمثل شبكة البطاقات المٌصدرة للبطاقة و ربما نوع الصناعة ( Airline, Healthcare , Petroleum )
الأرقام من 2 ل 6 : تمثل الرقم التعريفي للبنك المصدر للبطاقة BIN (Bank Identification Number) , ويمكن أن يتم استخدام أول 6 أرقام ( رقم شبكة البطاقات + BIN ) لتعريف شبكة البطاقات والبنك ونوع الصناعة
الأرقام من 7 إلى 15: تمثل رقم حساب العميل صاحب البطاقة Account Number
الرقم 16: هو Checksum Digit ويستخدم للتحقق من صلاحية البطاقة باستخدام خوارزمية Luhn اللي هنتكلم عنها في ورقة منفصلة باذن الله
تقسيم الرقم بهذا الشكل بيساعد ال Payment Processor في تحديد نوع البطاقة وشبكة البطاقات المٌصدرة له وإذا كان ال Payment Processor بيدعم طريقة الدفع بها أو لاء
كود الأمان الـ CVC
هو كود مكون من 3 أرقام عادة على ظهر البطاقة يٌستخدم عادة للتحقق من أن مستخدم البطاقة بيحمل البطاقة بشكل فعلي, لأن الرقم الأساسي ممٌكن يتسرق ولكن مش هيتم استخدامه بدون ال CVC و تاريخ الانتهاء.
لاحظ مُبرمجنا الفاضل إنه بموجب ال PCI-DSS فلا يجوز تخزين رمز CVV مع أي جهة بعد المعاملة.
تاريخ الإنتهاء
يٌمثل تاريخ إنتهاء صلاحية البطاقة ويٌحدده البنك المصدر للبطاقة
الشريحة Chip
تقوم الشريحة بحمل بيانات البطاقة وهي اللي بتخلي البطاقة ذكية وتقدر ال Terminals المختلفة تقرأها. ال Chip كمان بتقوم بدور كبير في حماية البطاقة لأنها لكل معاملة بتقوم بتوليد Cryptogram (رمز مميز) ودا بيقلل من خطر الاحتيال عن طريق نقل بيانات البطاقة.
الشريط الممغنط Magnetic Strip
دي كانت الطريقة القديمة لجعل البطاقة ذكية فهو كذلك بيحمل بيانات البطاقة ولكنه أقل أمانًا من استخدام الشريحة لأن يمكن نقل البيانات بسهولة من علي البطاقة لبطاقة أخرى, بعض البطاقات لازال عليها في حال كان قارئ البطاقة قديم ولا يدعم قراءة الشريحة.
شبكة البطاقات Card Network
يوجد علي البطاقة Logo شبكة البطاقات التي تستطيع معالجة هذه البطاقة, البنك يقوم بعمل Co-branding مع شبكة البطاقات, فالبنك هو المسؤول عن التحقق من البطاقة ولكن شبكة البطاقات هي التي توصل البنوك ببعضها البعض.
شبكة البطاقات بشكل عام فكرتها ابتدت من أن بنك ألف ليه أكثر من فرع وعشان يوصل بالبنك باء اللي عنده كذلك أكثر من فرع هيحتاج يحتفظ ببيانات كل بنك بكل فرع لهذا البنك عشان يعرف يتواصل معاه ويرسل/يستقبل الأموال منه وإليه , الموضوع مرهق علي النطاق المحلي ما بالك إن في لسه معاملات مع بنوك أخري خارج البلاد. فشبكات البطاقات بتقوم بموضوع التواصل دا وبتوصل البنوك ببعض.
البنك المصدر Issuing Bank
يوجد علي البطاقة Logo البنك المصدر للبطاقة, وبه يوجد حساب العميل وهو المسؤول عن التحقق من البطاقة و رصيد العميل.
How Discord Stores Trillions of Messages
في سنة 2017 فريق المهندسين في Discord نشروا مقال عن إزاي بيخزنوا مليارات الرسايل. وقتها شاركوا الرحلة بتاعتهم من حيث استخدام MongoDB لحد ما قرروا ينقلوا بياناتهم لـ Cassandra، وده لإنهم كانوا بيدوروا على قاعدة بيانات قابلة للتوسيع Scalable، بتتحمل الأخطاء Fault-Tolerant، وما تحتاجش صيانة كتير Maintenance.
ولإنهم كانوا عاوزين قاعدة البيانات تكبر معاهم، كانوا متأملين إن احتياجات الصيانة ما تكبرش بنفس معدل النمو بتاع التخزين. ولكن للأسف، ده ما كانش الحال - فمجموعة Cassandra بتاعتهم بدأت تظهر فيها مشاكل في الأداء كبيرة وكانت بتحتاج مجهود كبير عشان يحافظوا عليها، مش عشان يطوروها.
وبعد حوالي 6 سنين، اتغيرت حاجات كتير، والطريقة اللي بيخزنوا بيها الرسايل كمان اتغيرت.
Cassandra Troubles
فريق المهندسين في Discord كانوا بيخزنوا الرسايل في قاعدة بيانات اسمها cassandra-messages. وزي ما الاسم موضح، كانت شغالة بـ Cassandra وبتخزن الرسايل. في 2017، كانوا مشغلين تقريبًا حوالي 12 node لـ Cassandra، وكان عندهم مليارات الرسايل.
اما في بداية 2022، عدد الـ nodes زاد ووصل لـ 177 وعدد الرسايل بقى بالـ trillions. وللأسف، النظام ده كان بيحتاج صيانة كتير جدًا — والفريق اللي على الـ on-call كان بيتبعت له تحذيرات كتير عن مشاكل في الـ database، والـ latency كان غير متوقع إطلاقًا، وكانوا مضطرين يوقفعوا عمليات الصيانة لأنها كانت بتاخد وقت ومجهود كبير من الفرق.
إيه اللي كان مسبب المشاكل دي؟ خلينا نبص على الرسالة نفسها.
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);الـ CQL statement اللي فوق هو نسخة مبسطة من الـ schema بتاعت الرسايل. كل الـ IDs اللي بيستخدموها هي عبارة عن Snowflake، ودي Service من Twitter عشان تـ Generate IDs فبالتالي ده بيخليها sortable بشكل زمني.
وبيعملوا partition للرسايل على حسب الـ channel اللي اتبعتت فيه، بالإضافة للـ bucket، اللي هو عبارة عن Window كده زمنية ثابتة. الـ partitioning ده بيخلي كل الرسائل اللي في channel و bucket معينين تتخزن مع بعض وتكون مكررة على 3 nodes (أو حسب الـ replication factor اللي متظبط).
لكن جوه الـ partitioning ده في مشكلة محتملة في الأداء الا وهي: السيرفر اللي فيه عدد قليل من الأعضاء بيبعت رسائل أقل بكتير جدًا مقارنة بالسيرفر اللي فيه مئات الآلاف من الناس. طب ده هيعمل مشكلة في ايه ؟ خلونا نكمل ..
في Cassandra، الـ reads بتكون تقيلة شويتين وHeavier من الـ writes. وده لإن الـ writes اصلًا بتتضاف في الـ commit log وبتتكتب بعد كده في structure موجود في الـ memory اسمه memtable اللي بعد كده بيتحفظ على الـ disk ويتعمله Flushing.
أما الـ reads، فهي بتحتاج تقرا من الـ memtable وكمان ممكن تحتاج تقرا من كذا SSTable (ملفات موجودة على الـ disk)، ودي بتكون عملية تقيلة شويتين. فالـ reads الكتير اللي بتحصل في نفس الوقت مع تفاعل المستخدمين مع السيرفرات بتسبب حاجة بنسميها "hot partition" وهي دي المشكلة اللي بتنتج من الـ Partition بناء على الـ Channel. وحجم الـ dataset بتاعة Discord، مع نمط التفاعل ده، عمل مشاكل في الـ cluster ككل.
فلما كانوا بيقابلوا hot partition، ده كان بيأثر على الـ latency في الـ cluster كله. ولما الـ node بتاخد وقت أطول عشان تخدم الـ Traffic، كل الـ queries التانية اللي رايحة للـ node كانت بتعاني من نفس التأخير، وده لإنهم كانوا شغالين بالـ Quorum Consistency Level وده كان بيزود تأثير المشكلة على المستخدمين بالتأكيد.
كمان مهام الصيانة كانت بتعمل مشاكل كتير جدًا. فكانوا دايمًا متأخرين في عملية الـ compactions، اللي فيها Cassandra بتدمج الـ SSTables على الـ disk علشان تحسن أداء الـ reads. وده كان بيخلي الـ reads تقيلة، وكانوا بيشوفوا تأخير أكبر لما الـ node كانت بتحاول تعمل compact.
بالإضافة لإنهم كانوا بيعملوا عملية اسمها "gossip dance"، اللي فيها بنخرج الـ node من الـ rotation علشان نديها فرصة تعمل compact من غير أي Traffic تستقبله، وبعدين يرجعوها تاني علشان تلتقط الـ hints من hinted handoff، ويكرروا العملية لحد ما الـ backlog بتاع الـ compaction يخلص.
وكانوا بيقضوا وقت طويل برضه في تعديل إعدادات الـ JVM's garbage collector والـ heap settings، لأن الـ GC pauses كانت بتسبب ارتفاع كبير في الـ latency.
Changing Architecture
مجموعة الرسايل ما كانتش هي الـ Cassandra cluster الوحيدة اللي Discord بيشتغل عليها بالتأكيد. وكان فيه أكتر من cluster تاني، وكلهم كانوا بيعانوا من مشاكل مشابهة (ولو إن كانت مشاكل الرسايل هي الأصعب بالنسبالهم).
في المقال اللي نشروه قبل كده، اتكلموا عن إنهم كانوا مهتمين بـ ScyllaDB، وهي Database متوافقة مع Cassandra مكتوبة بلغة C++. والوعود بتاعتها كانت بتقول إنها أسرع، بتصلح المشاكل بشكل أسرع، وعندهاعزل أفضل للـ workload بسبب الـ shard-per-core architecture بتاعتها، وما فيش فيها مشكلة الـ garbage collection.
ورغم إن ScyllaDB مش خالية من المشاكل، بس هي خالية من الـ garbage collector، لأنها مكتوبة بـ C++ بدل الـ Java. وتاريخيًا، فريق مهندسين Discord كان بيعاني مع الـ garbage collector في Cassandra، من الـ pauses اللي بتأثر على الـ latency، لحد pauses طويلة جدًا كانت بتوصل لدرجة إن لازم شخص من الفريق يعيد تشغيل الـ node ويهتم بيها بشكل يدوي.
المشاكل دي كانت سبب كبير في الـ on-call، وجذور كتير من المشاكل اللي كنا بنواجهها في stability.
فبعد ما جربوا ScyllaDB وشافوا تحسينات، قرروا ينقلوا كل قواعد البيانات بتاعتهم ليها. وبالرغم إن القرار ده ممكن يكون في مقال تاني لوحده منفصل خالص، فباختصار في 2020 كانوا نقلوا تقريبًا كل قواعد البيانات ما عدا واحدة لـ ScyllaDB.
والـ database اللي كانوا لسه ما قاموش بنقلها هي: cassandra-messages.

Why Cassandra-Messages Not Migrated
لأن الـ cluster ده كان كبير جدًا. ومع تريليونات من الرسايل وحوالي 200 node، أي عملية نقل هتكون معقدة جدًا. وكمان، كانوا عاوزين يتأكدوا إن الـ database الجديدة هتبقى بأفضل أداء ممكن وكانوا محتاجين خبرة أكتر مع ScyllaDB في الـ production عشان يفهموا أكتر المشاكل اللي ممكن تقابلهم والتحديات اللي هتكون قدامهم.
Concurrency Building Blocks (Threads)
الـ Concurrent Programming مبنية على فكرة إن يكون عندي الـ Application متكسر لـ Independent Tasks يعني مهام مستقلة أو Units اقدر اشتعل عليهم بشكل Concurrently.
وطبعًا الـ Abstraction Layer واللي بتسهلنا أغلب الشغل ده ألا وهو الـ OS قادر إنه يدير الـ Tasks دي ويعملهم Handling بشكل كويس من خلال إنه يوفر الـ Resources اللازمة بشكل كفء.
فنقدر نعتبر الـ Concurrent Programming هي مجموعة من الـ Abstractions اللي بتسمح للمطورين إنهم ينظموا التطبيق بتاعهم على شكل مهام صغيرة ومستقلة وينقلوها بعد كده للـ Runtime System واللي في الحالة دي هو الـ OS عشان يعملهم Handling بكفاءة.
وطبعا الـ Runtime System هيكون المسئول عن تنفيذهم وعملية الـ Orchestration اللي هتتم بينهم عشان يختار انهي Task اللي هيتم تنفيذها ويستغل الـ Resources بأفضل شكل ممكن.
وخلاصة الـ Abstractions اللي عمالين نتكلم عليها دي هي إن احنا عندنا بكل بساطة نوعين من الـ Abstractions كمطورين عشان نتعامل مع الـ Concurrent Programming والنوعين دول هم الـ Building Blocks اللي ممكن نعتمد عليهم عامة في تطبيق الـ Concurrency ألا وهم الـ Process والـ Threads.
اتكلمنا المرة اللي فاتت عن الـ Process وشوفنا مع بعض شوية من الـ Internals بتاعتها وقد ايه موضوع إنشاء أو حذف Process هي عملية مكلفة وشوفنا ازاي هي بتتميز بالاستقلالية والعزل.
المرة دي هنتكلم عن تاني Building Block في الـ Concurrent Programming ألا وهي الـ Threads.
الـ Threads
مشاركة الـ memory بين الـ processes وبعضها ممكنة في معظم الـ OSs، بس محتاجة مجهود إضافي مننا كمطورين للتعامل معاها. وعشان كده فيه abstraction تاني بيسمح لينا بمشاركة الـ memory بشكل فعال أكتر: وهو الـ threads.
في النهاية، البرنامج بتاعنا هو مجرد مجموعة من الأوامر اللي لازم تتنفذ واحدة ورا التانية بالترتيب. وعشان ده يحصل، الـ OS بيستخدم مفهوم الـ thread. من الناحية التقنية، الـ thread بتتعرف على إنها سيل مستقل من التعليمات اللي الـ OS ممكن يجدول تنفيذها.
فاكرين لما قولنا إن الـ process هو برنامج شغال بالإضافة لشوية موارد معمولها Allocation ليه؟
لو قسمنا البرنامج لمكونات منفصلة، الـ process بتكون هي الـ container للموارد دي زي (address space، ملفات، اتصالات، إلخ)، والـ thread هي الجزء الديناميكي— مجموعة من التعليمات بتتنفذ جوة الـ container.

الـ threads اتولدت من فكرة إن أسهل طريقة لمشاركة البيانات بين الـ processes اللي بتتفاعل مع بعض، هي إنهم يشاركوا الـ (address space). وعشان كده، الـ threads اللي في نفس الـ process، نقدر نعتبرهم زي الـ processes اللي ممكن تشارك الموارد بسهولة مع بعض ومع الـ parent process بتاعتهم، وكذلك الـ address space، والملفات، والاتصالات، والبيانات المشتركة، وهكذا.
الـ threads كمان بتحافظ على الحالة بتاعتها عشان تسمح بالتنفيذ الآمن والمستقل للتعليمات بتاعتها. كل thread مش واخدة بالها من الـ threads التانية إلا لو كانت بتتداخل معاهم عن قصد.
فالـ OS بيدير الـ threads وممكن يوزعهم على الـ CPUs المتاحة. وعشان كده، تطوير برنامج multithreaded ممكن يكون طريقة سهلة لتشغيل كذا task في نفس الوقت بالنسبة لكتير من الناس.
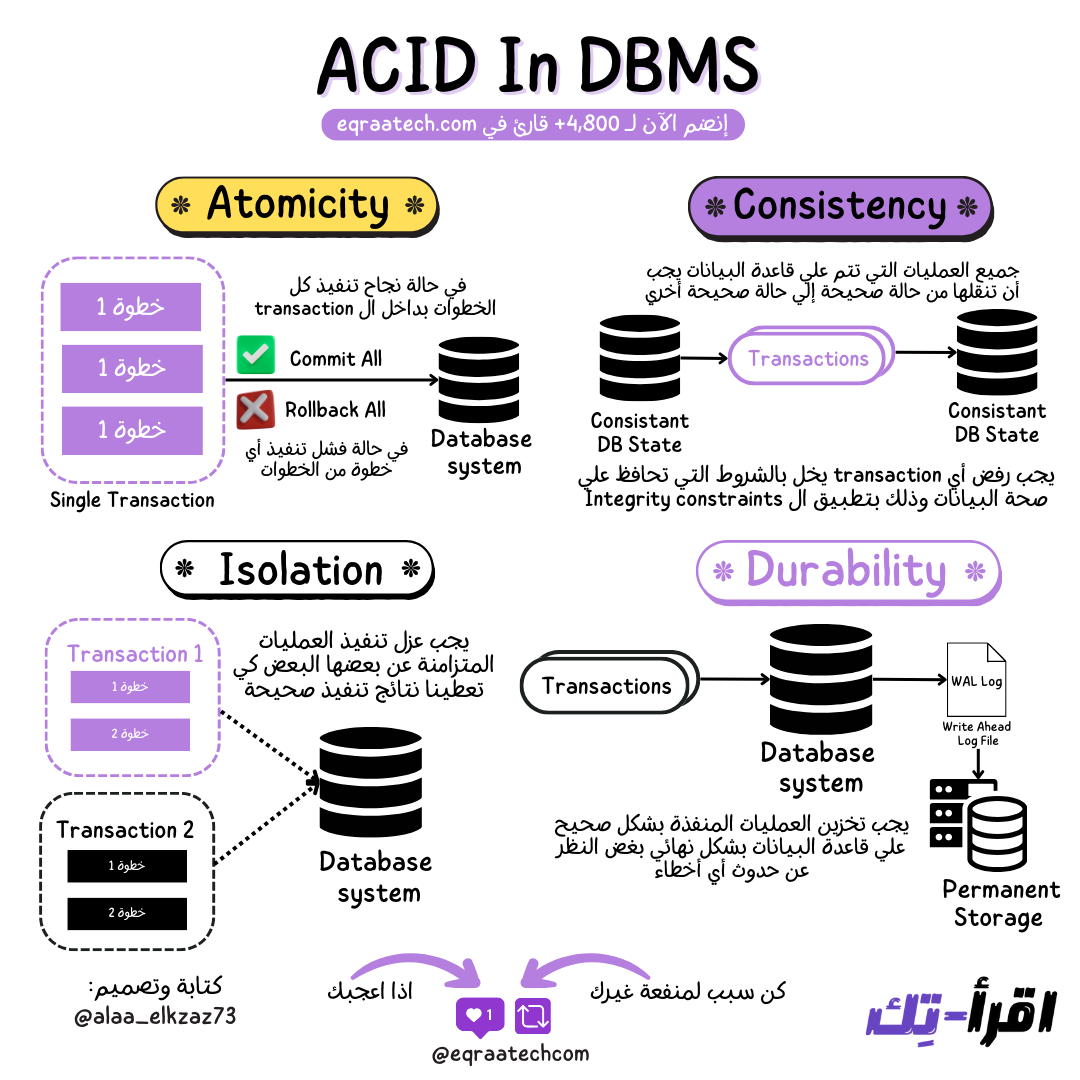
ACID Properties in DBMS
من المفاهيم الاساسية والشهيرة في الـ Relational Databases هي الـ ACID فورقة وقلم وتعالوا نعرف هي إيه وليه مهم إن قاعدة البيانات تكون بتحققها.
ال ACID ببساطة عبارة عن اختصار ل 4 قواعد لازم تحققهم قاعدة البيانات و العمليات اللي بتتم عليها بغض النظر عن أي Software or Hardware Failure أو حتى Power Failure.
و ال 4 قواعد دي هي الضمان إن ال Database دي والبيانات اللي فيها صحيحة وموثوق فيها و دا عامل أساسي في مجال البرمجيات ككل "صحة البيانات".
ال 4 قواعد هما:
Atomicity
Consistency
Isolation (Safe Concurrent Transactions Execution)
Durability(Committed Transactions Must Be Durable)
Atomicity
القاعدة دي بتقول ان ال Transaction الواحد واللي بيعني "عملية مفيدة كاملة من وجهة نظر النظام" يا اما يتنفذ كله يا ما يتنفذش خالص, فمثال على ال Transaction لو شغال علي برنامج لبنك هيكون عملية نقل الأموال من حساب للتاني العملية دي كلها مع بعض البرنامج هينفذها على 3 خطوات:
اتاكد ان الحساب فيه 100 جنيه
خصم 100 جنيه من الحساب
احط 100 جنيه في حساب الطرف الثاني
فهنا القاعدة بتقول ان لازم ننفذ كل الخطوات دي مع بعض كعملية واحدة، ولكن في حالة فشل أي خطوة في النص فلازم يحصل تراجع عن كل الخطوات اللي تم تنفيذها مسبقًا - بمعنى اصح Rollback - لأنها هتحط قاعدة البيانات في حالة غير مفهومة وغير صحيحة لو ما تراجعناش عن كل الخطوات اللي اتنفذت قبلها.

خصم 50% على جميع خطط الاشتراك السنوية لفترة محدودة، تقدروا دلوقتي تشتركوا في اقرأ-تِك وتستمتعوا بكافة المقالات في كل ما يخص هندسة البرمجيات باللغة العربية والمحتوى المميز من ورقة وقلم ومدونات فطين اللي بيتميزوا بتصاميم ذات جودة عالية وكل ده بحرية كاملة وكمان مفاجآت اقرأ-تِك الجاية 🚀
وبرضو متاح الاشتراك من خلال InstaPay و VodafoneCash 🎁

مدونات فطين في تصميم النظم - الإصدار الأول 🚀

كتابة هذا الكتاب لم تكن قرارًا مخططًا... بل كانت نتيجة لتراكمات من الحيرة، الإحباط، والدهشة اللي بيواجهوا أغلب الشباب حاليًا خصوصًا في رحلة البحث عن تعلم مهارات تصميم النظم واللي أصبحت من المهارات الأساسية في الانترفيوهات بالإضافة لكونها مهمة فعلًا على جميع المستويات.
على مدار سنوات من العمل داخل شركات تكنولوجية متعددة، وجدت نفسي مرارًا أواجه بعض الأسئلة زي:
لماذا صُمّم هذا النظام بهذه الطريقة؟
لماذا لم نرَ المشكلة إلا بعد فوات الأوان؟
هل كان يمكن أن نصمم الأمر بشكل أبسط؟
الإجابات كانت دائمًا معقدة، وتعود لأبعاد تقنية وتنظيمية ونفسية أيضًا.
هذا الكتاب ليس دليلًا أكاديميًا، بل هو مجموعة من التجارب والخبرات العملية كتبتها بعين المهندس الذي يراقب، يسأل، ويُخطئ ثم يتعلّم. المجموعة دي لم يتم ترجمتها للعربية من مدونات الشركات العالمية .. بل تم اعادة شرحها وتبسيطها باللغة العربية بأسلوب مختلف حتى تتسم بالبساطة بالإضافة لتميزها بالرسوم التوضيحية الجذابة.
اخترت اسم "فَطين" لأنه الشخصية التي تمنيت لو كانت موجودة معي منذ البداية— يسأل الأسئلة الصحيحة، ويفكّر بصوت عالٍ، ويحكي لك الدروس المستفادة.
إن كنت مهندسًا في بداية الطريق، أو تعمل منذ سنين ولديك خبرة متوسطة أو متقدمة في تصميم وبناء النظم فهذا الكتاب كتبته لك ليكون مرجعًا عمليًا لك يساعدك في تطوير مهاراتك التحليلية والفكرية في بناء وتطوير النظم الضخمة.
يتناول الكتاب ما يعادل من 15 تجربة عملية مميزة من داخل الشركات العالمية في تصميم النظم الضخمة بأكتر من 160 صفحة ويضم الآتي :
Introduction Into System Design
How Uber Serves Over 40 Million Reads Per Second
How Discord Stores Trillions of Messages
Dropbox's Chrono: Scalable, Consistent and Metadata Caching Solution
Unlocking Notion's Power - The Data Model Explained
How Shopify Mitigates Deadlocks in High Concurrency Environments
How LinkedIn Improves Microservices Performance With Protobuf
How Figma Secures Internal Web Applications
How GitHub Improves Reliability of Code Push Processing
How Meta Leverages AI For Efficient Incident Response
How Stripe Architected Massive Scale Observability Solution on AWS
Change Data Capture at Pinterest
How Canva Built Scalable and Reliable Content Usage Counting Service
How Netflix Migrates Critical Traffic at Scale With No Downtime
How Slack Handles Billions of Tasks in Milliseconds
How YouTube Supports Billions of Users With MySQL
System Design Comprehensive Guide
تقدروا تشوفوا النسخة كاملة من هنا كـ E-Book ، وحاولنا نخليها بسعر رمزي يناسب الجميع 👇
وكمان وفرناه على Kindle عشان الناس اللي بتحب تجربة القراءة على الـ Kindle منحرمهاش من التجربة الممتعة دي 🎉

بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship واحنا بنرحب بجميع الشراكات مع المؤسسات والشركات وأصحاب الأعمال لبناء مجتمع عربي يشجع على القراءة والتعلم ومشاركة التجارب والخبرات العملية في هندسة البرمجيات.
دورك كشريك أو راعي هيكون محوري في دعم المحتوى وتوسيع نطاق تأثيره. فانضم لرحلتنا وكن جزءًا من صناعة مستقبل التكنولوجيا في المنطقة 🚀
تقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 👇

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
