
VOL39: How Stripe Architected Massive Scale Observability Solution on AWS
أهلًا وسهلا بكم في العدد التاسع والثلاثين من النشرة الأسبوعية لاقرأ-تِك 🚀


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد التاسع والثلاثين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية، من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة، ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

How Stripe Architected Massive Scale Observability Solution on AWS
Deep Dive Into SQL Window Function: Explained Visually Part 1
CQRS Architecture Pattern
CQRS and Mediator Pattern Overview
Date & Time Best Practices
ستجدون أيضًا في هذه النشرة:
تشويقة بخصوص شكل اقرأ-تِك الجديد 🎉
الشراكات - Sponsorship
قناة التليجرام مجانية للجميع حتى يصلك كل مقال جديد
كيفية كتابة مقالات معنا في اقرأ-تِك: والمقالات تكون متاحة ومجانية للجميع ومحفوظة باسم الكاتب بكل تأكيد
كيفية الاشتراك في اقرأ-تِك من خلال InstaPay و VodafoneCash
تشويقة 🎉
بقالنا فترة شغالين على شكل اقرأ-تِك الجديد وبعض الاصدارات الجديدة اللي باذن الله تنال اعجابكم ، فانتظروا قريبًا جدًا جدًا اقرأ-تِك في رونقها الجديد ، بالاضافة لاصدارات جديدة وتجربة سلسة وممتعة لقراءة كل ما يخص هندسة البرمجيات بالعربي 🚀
دعواتكم لينا بالتيسير ، وان شاء الله تجدوا كل ما تحبونه 👋
How Stripe Architected Massive Scale Observability Solution on AWS
شركة Stripe هي شركة متخصصة في توفير حلول الدفع سواء أونلاين أو في التعاملات الشخصية، وكمان بتوفر خدمات مالية للشركات بمختلف أحجامها. وطبعًا الشركة شغالة بنظام الـ Microservices وهو نظام معقد جدًا ومبني على AWS.
خلونا في رحلتنا انهاردة نتعرف على الرحلة والتحديات اللي قابلتها Stripe، والحلول اللي استخدمتها لما قررت تنقل نظام الـ (Observability Solution) بتاعها للمستخدمين على Amazon Managed Service for Prometheus (AMP).
الوضع قبل الـ Migration
قبل ما تبدأ Stripe عملية الـ Migration ، كانت بتتعامل مع أكتر من:
300 مليون metric.
40 ألف alert.
100 ألف Queries بتحصل على الـ Dashboards.
وده كله كان بيتم من خلال حوالي 7,000 موظف ، والشركة كانت معتمدة على time-series data platform كحل لمراقبة الـ metrics بتاعتها. ولكن واجهتهم بعض المشاكل زي:
الـ Scalability limits: نظام الـ Observability ماكنش بيستحمل الحجم ده من الـ Metrics , Alerts والـ Queries اللي بتحصل على الـ Dashboard.
الـ Reliability issues: مشاكل في استقرار النظام.
الـ Increased cost: تكلفة متزايدة مع استمرار استخدام النظام ده.
التحديات
أكبر تحديين كانوا بيواجهوا Stripe في الـ Third-Party Vendor Solution اللي كانوا بيستعملوه هما:
التكلفة
الـ Scalability: وده لإن كل ما نظام الـ microservices بتاعهم زاد تعقيدًا، ظهرت الحاجة لحل أكتر كفاءة من حيث التكلفة والـ Scale.
عشان كده قرروا ينقلوا تخزين الـ metrics بتاعتهم لـ Amazon Managed Prometheus.
نظرة سريعة على الحل
شركة Stripe قررت تتبع خطة من 4 مراحل لنقل النظام وعملية الـ Migration ككل والخطة كانت:
اعتمادهم على الـ Dual-write: وده معناه إنهم هيكتبوا الـ metrics على النظام القديم والجديد في نفس الوقت.
الـ Translation: وده من خلال تحويل الـ alerts والـ dashboards الحالية للغة PromQL وAmazon Managed Grafana عشان تبقى متناسبة معاها.
الـ Validation: التأكد من صحة البيانات اللي تمت ترجمتها عشان تبقى Compatible مع النظام الجديد والـ metrics المكتوبة.
الـ Migration of users' mental models: تغيير طريقة تفكير المستخدمين عشان تتناسب مع Prometheus.
خلونا نشوف الـ Architecture كان عامل ازاي اثناء الـ Migration Process بتاعتهم:

{kind=link}
Collection
الـ Collection (جمع البيانات):
الـ Metrics بيتم جمعها من خلال :
الـ host applications (ودي التطبيقات اللي شغالة على الـ servers).
الـ Kubernetes clusters (وده من خلال عملية scraping).
البيانات دي بتتبعت بعد كده للـ Aggregation Layer.
Aggregation
الـ Aggregation (تجميع البيانات):
في المرحلة دي، الـ shuffler بيبعت البيانات للـ host الصح.
الـ Aggregator بيعمل حاجات أساسية لتقليل الحجم الـ Cardinality زي إنه:
بيحسب المتوسطات (averages) للـ gauges.
بيجمع الـ counters.
بيحسب الـ percentiles.
طب يعني ايه Cardinality Reductions ؟
هي عملية بنقوم بيها عشان نقلل عدد العناصر أو البيانات الفريدة اللي بيتعامل معاها النظام لما بيحلل أو بيخزن البيانات وبيكون الهدف منها هو تحسين أداء النظام وتقليل استهلاك الموارد زي التخزين والمعالجة.
طب ليه ممكن نحتاج لحاجة زي كده ؟
لما تبقى الـ metrics فيها عدد كبير جدًا من القيم الفريدة (unique values)، ده ممكن يعمل مشاكل زي:
زيادة استهلاك الذاكرة (Memory Usage): كل قيمة فريدة لازم يكون ليها مكان في التخزين.
بطء في معالجة البيانات (Processing): النظام بياخد وقت أطول لما العدد يزيد.
زيادة التكلفة: سواء من ناحية التخزين أو استهلاك الموارد.
وعشان كده الـ Aggregator كان من ضمن مهامه الأساسية إنه يقلل من الـ Cardinality على قد ما يمكن.
Deep Dive Into SQL Window Function: Explained Visually Part 1
المقال ده هو الجزء الأول من سلسلة مقالات هنتكلم فيها عن sql window functions ، في المقال ده هنشرح ازاي الـ window functions بتشتغل وايه الفرق بينها و بين الـ aggregate functions وهنتكلم عن 3 window functions مشهورين وهم: RANK, DESNE_RANK, ROW_NUMBER، و هنشوف خلال المقال امتى الـ functions دي ممكن تكون مفيدة وايه المشاكل اللي بتحلها.
ما هي ال Window Function ؟
عشان نعرف يعني ايه window function هنبدأ بمثال، في المثال ده عندنا جدول فيه بيانات موظفين في شركة

واتطلب مننا نحسب متوسط المرتبات لكل قسم، حاجة زي كدة نقدر نعملها عن طريقة إننا نستخدم AVG ونعمل group by الـ departmentID، وده الكود اللي هينفذ المطلوب:
SELECT departmentId, AVG(salary) AS average_salary
FROM employee
GROUP BY departmentId
ودي النتيجة اللي هتطلع:

ولكن لو اللي طلب مننا نحسب متوسط المرتبات لكل قسم لما شاف النتيجة دي قال إنه مش عايز الشكل ده اللي هو الـ ID بتاع كل قسم وجنبه متوسط المرتبات فيه ولكن هو عايز يبقى قدامه بيانات الموظفين كلها تكون ظاهرة هي ومتوسط المرتبات لكل قسم الاتنين في نفس الجدول بمعنى إني عايز قدام كل موظف متوسط المرتبات في القسم اللي هو شغال فيه، باختصار عايز النتيجة تكون بالشكل ده:

شكل زي ده صعب نوصله باستخدام AVG مع group by، لان AVG دي aggregate function ومعنى كدة إنها بتعمل عملية معينة اللي هي المتوسط على مجموعة صفوف وترجع النتيجة في صف واحد بس، ولما أستخدم group by ده هيخلي عندي صف واحد بس لكل قسم، ففي المثال ده عندي 3 أقسام فالنتيجة ظاهر فيها 3 صفوف بس، فالسؤال هنا: ازاي أحسب متوسط المرتبات لكل قسم و في نفس الوقت النتيجة يبقى فيها نفس عدد صفوف الجدول الأصلي ويبقى عندي قدام كل موظف متوسط المرتبات في القسم اللي هو شغال فيه؟ دي الحاجة اللي الـ window functions بتعملها لنا.
الـ window function هي function بتعمل عملية معينة على مجموعة صفوف في الجدول من غير ما البيانات اللي في الجدول الأصلي تروح مني زي ما بيحصل لما أستخدم aggregate function.
الشكل ده بيوضح ازاي الـ window function والـ aggregate function مختلفين عن بعض:
CQRS Architecture Pattern
بناء البرمجيات زي بناء المباني بالظبط محتاج ترتب أجزاء المبني وعلاقتهم ببعض بطريقة مناسبة لوظيفة المبني والمستخدمين, فالبيت مبني وكذلك الجامعة مبني ولكن الحجم, والوظيفة والمستخدمين مختلفين ومن هنا بتيجي فكرة ال Architectural Patterns في البرمجيات.
والشطارة بتكون في ازاي استخدم النمط الأكثر إفادة لوظيفة وحجم ونوع الاستخدام لمشروعي اللي شغال عليه.
Command Query Responsibility Segregation (CQRS)
في معظم مشاريعنا بنستخدم CRUD Pattern وبنعتمد علي الوظائف الأساسية فيه زي Create, Read, Update, Delete وبالفعل هو نمط مناسب للمشاريع البسيطة والصغيرة والمتوسطة في الحجم لأنه سهل.
ولكن في حالات بنحتاج فيها Data Manipulation اكثر من الـ CRUD يقدر يقدمه , زي اننا نشتغل في Business العلاقات فيه بين ال objects معقدة أكتر أو تطبيق يكون فيه استهلاك البيانات فيه عالي وكذلك كتابتها ودا بيوقعنا في مشكلة لأن متطلبات الـ Scaling في حالة الـ Heavy Reads تختلف عن متطلباته في حالة الـ Heavy Writes
ال CQRS اختصار لـ Command Query Responsibility Segregation أو Separation وهو نمط هدفه الفصل بين الـ Commands و الـ Queries في الكود وبنعّرف فيه:
الأوامر (Commands): : هي عملية كتابة أو تغيير البيانات وهي العمليات اللي فيها بتتغير حالة النظام. والأوامر جي بتقوم بـ "فعل" شيء وتؤثر على حالة النظام.
الاستعلامات (Queries): عملية قراءة البيانات وهي العمليات اللي بتسترجع بيانات و لكن لا تغير حالة النظام. بمعنى أنها "تسأل" عن شيء معين ولا تعدل أي شيء.
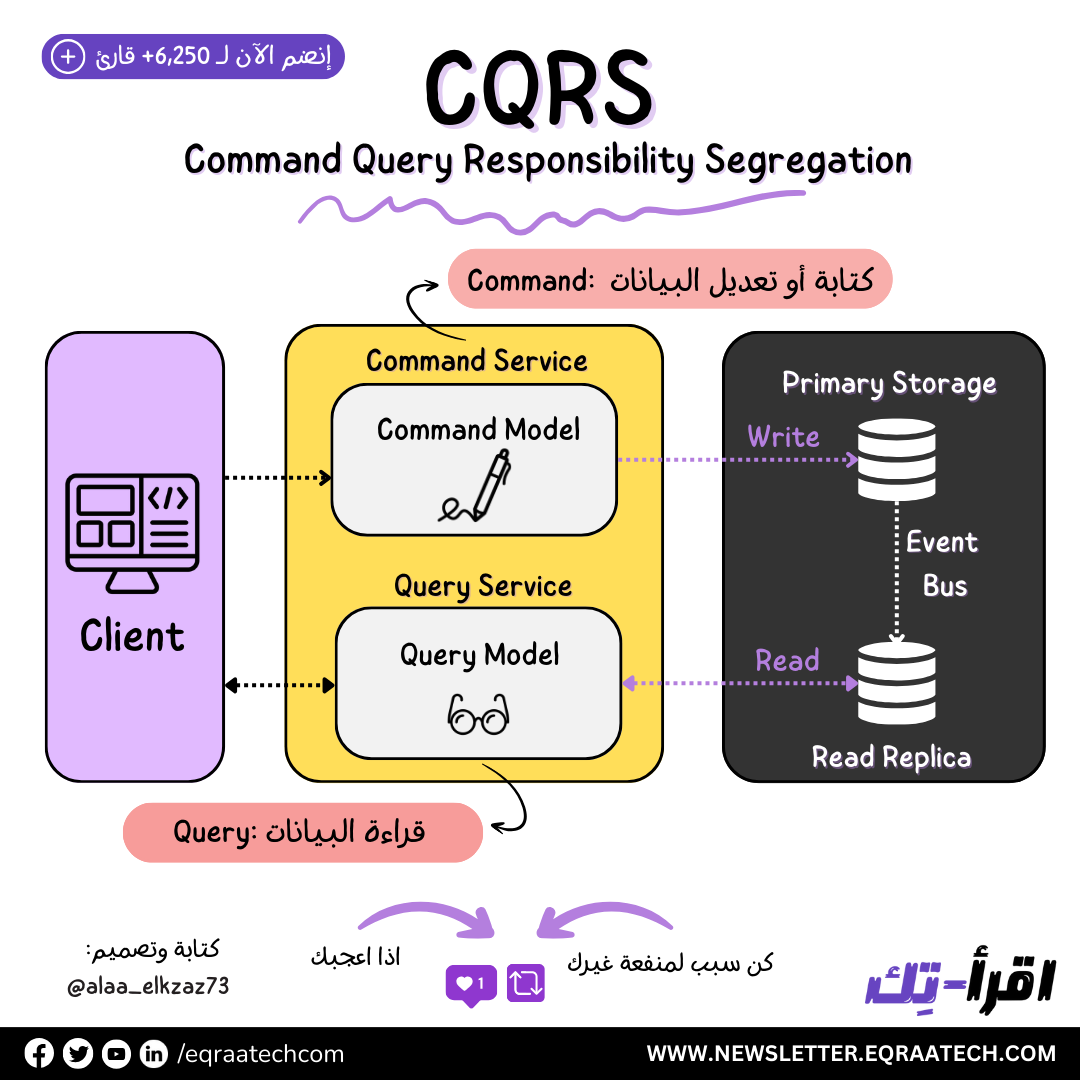
الـ CQRS يستخدم اثنين من الـ Models المختلفة عشان يحقق الأوامر (Commands) بالـ Model المناسب ليها و كذلك Model خاص بالـ للاستعلامات (Queries). وبما إن دا Architectural Pattern فبيسيب للمبرمج حرية اختيار وتنويع الـ Models اللي شايفها بتحقيق الهدفين دول وايه الأنسب لمشروعه وده بيدينا مرونة في التنفيذ.
كمان نقدر في تنفيذه نستخدم 2 من قواعد البيانات -الطريقة الأكثر شيوعًا- واحدة مخصصة للاستعلامات وواحدة للأوامر ويتعمل بينهم Synching.
الشراكات - Sponsorship
بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship وتقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 🚀
لا تدع شيء يفوتك!

بفضل الله قمنا بإطلاق قناة اقرأ-تِك على التليجرام مجانًا للجميع 🚀
آملين بده اننا نفتح باب تاني لتحقيق رؤيتنا نحو إثراء المحتوى التقني باللغة العربية ، ومساعدة لكل متابعينا في انهم يوصلوا لجميع أخبار اقرأ-تِك من حيث المقالات ومحتوى ورقة وقلم والنشرة الأسبوعية وكل جديد بطريقة سريعة وسهلة
مستنينكوا تنورونا , وده رابط القناة 👇
CQRS and Mediator Pattern Overview
الـ CQRS هو Pattern نمط بيفصل بين العمليات اللي بتعمل استعلامات (queries) والعمليات اللي بتنفذ أو بتعدل بيانات (commands) في التطبيق. الفصل ده بيسمح لك إنك تستخدم different data models موديلات بيانات مختلفة لكل حالة، وبالتالي التطبيق بيبقى أكتر مرونة.
التعديلات اللي بتعملها مش هتأثر على باقي الأجزاء في التطبيق، وده لأن مفيش حاجة هتحتاج lock tables or records قفل جداول أو سجلات عشان تعمل updates تحديثات، وده كان بيؤثر سلبًا على الأداء.
كمان تقدر تخصّص البيانات حسب احتياجات الاستعلامات(queries) ، وده بيسمح لك كمان تستخدم تقنيات تخزين مختلفة بناءً على احتياجات الاستعلام(queries). بالإضافة لذلك، تقدر توزع وتكبر عمليات القراءة والكتابة بشكل منفصل، وده بيخلي استهلاك الموارد أكتر كفاءة وأقل تكلفة في البنية التحتية.
دي صورة بتوضح المشكلة :

ودي صورة بتوضح الحل بتطبيق ال CQRS :

خدت بالك من ال DAL في الصورتين :
لما التطبيق بيقرأ بيانات، ممكن يحتاج ينفذcomplex queries استعلامات معقدة عشان يطلع Data Transfer Object (DTOs) في هياكل مختلفة different structures، وده ممكن يسبب تعقيد في عملية تحويل البيانات . (object mapping)
من ناحية تانية، لما بيكتب بيانات، النموذج ممكن يحتوي على عمليات تحقق معقدة (validation) و (business logic)، وده ممكن يخلي الmodel يبقى معقد جدًا وبيتحمل multiple responsibilities مسؤوليات كتير.
وده اللي هتلاقيه اتعالج واتصلح في الصورة التانية باستخدام ال CQRS .
Mediator Pattern
طيب فهمنا المشكلة والحل ايه بقى موضوع ال Mediator pattern ده ؟
ال Mediator pattern بيهدف لتقليل الاعتمادية بين الكائنات (objects) يعني بي reduce dependencies between objects وده من خلال انه بيمنع الاتصال المباشر بينهم.
طيب بيكلموا بعض ازاي ؟ بيكلموا بعض عن طريق كائن وسيط (mediator).
ببساطة، فيه كائن واحد (mediator) بيتولى تنظيم وإدارة كيفية تفاعل الكائنات (objects) التانية مع بعض. يعني بدل ما الكائنات (objects) تتكلم مع بعض بشكل مباشر، هي بتتواصل مع الوسيط (mediator) اللي بيشوف ويدير التفاعل بينهم.
طيب وايه كانت المشكلة عشان يخترعو ال Mediator pattern ؟
المشكلة كما بالشكل :
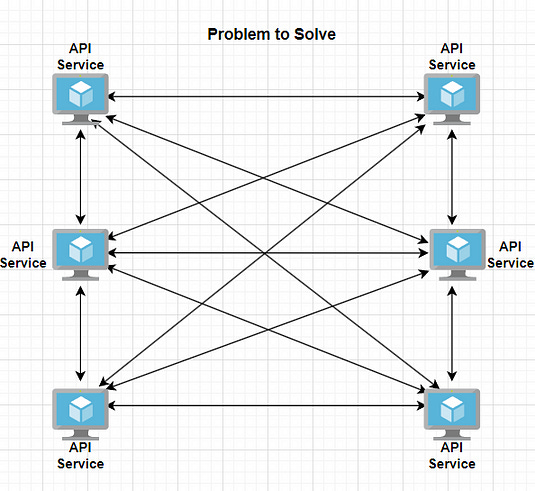
هتلاقي هنا ال objects بتتواصل بشكل مباشر بتكون عادة مترابطة بشكل قوي (tightly coupled). في الحالات دي، أي تغيير في object واحد ممكن يؤثر على الكائنات التانية، وده بيؤدي لتغييرات تانية في النماذج (models)، السكربتات (scripts)، وغيرهم.
Date & Time Best Practices
في يوم مشمس جميل في الشغل جالك مشروع برمجة تطبيق لشركة طيران يقدر المستخدم يستعمله في حجز التذاكر, طبعًا فرحت جدًا ما كلنا بنحب السفر لحد ما فكرت في مشكلة التاريخ والوقت وجالك صداع!
هخلي التطبيق يحسب التاريخ والوقت على أساس أنهي دولة؟ طيب هعمل ايه في التوقيت الصيفي؟ وبالنسبة للمناطق الزمنية؟!, طيب ايه اللي هيحصل في السنين الكبيسة!!
مشاكل التعامل مع التاريخ والوقت في صناعة البرمجيات غنية عن التعريف لأن الموضوع فعلاً معقد فورقة وقلم وتعالوا نتعرف على أفضل الطرق للتعامل معها.

1- استخدم مكتبة موثوقة
القاعدة الأهم في موضوع دوال الوقت و التاريخ إنه لازم تستخدم مكتبة موثوق فيها سواء موجودة في اللغة بشكل أساسي زي datetime في python أو java.time في java
ابعد تمامًا عن إعادة اختراع العجلة ومحاولتك لبرمجة الدوال دي بنفسك لأن الساعة كما نعرفها الآن تعرضت لتغييرات تاريخية وسياسية وجغرافية بتخلي موضوع برمجة دوال الوقت والتاريخ بشكل صحيح من الصفر مشروع معقد جدًا.
لازم كمان تضمن إن المكتبة اللي بتستخدمها بتوفر بيانات محدثة ودقيقة عن المناطق الزمنية.
2- استخدام الـ UTC لتجنب مشاكل الـ Timezones
ال UTC هو نظام توقيت عالمي موحد بنستخدمه عشان نتجنب الالتباس في الساعات والمناطق الزمنية حوالين العالم, فخلي دايمًا برنامجك معتمد عليه بشكل أساسي بدل ما تستخدم الوقت المحلي للمنطقة أو الدولة اللي أنت فيها. وممكن بسهولة تقدر تعمل formatting ليه عشان يظهر الوقت المحلي للمستخدم.
فكمثال عندما يقوم مستخدم بحجز رحلة من نيويورك (UTC-5) إلى باريس (UTC+1)، يجب على النظام أن يحسب بدقة وقت المغادرة ووقت الوصول في المنطقة الزمنية المحلية.
إذا كانت الرحلة تغادر نيويورك في الساعة 6 مساءً بالتوقيت المحلي وتستغرق 7 ساعات، يجب أن يعرض النظام وقت الوصول في باريس بالتوقيت المحلي الصحيح (الساعة 2 صباحًا بتوقيت باريس).
3- التوقيت الصيفي
احنا خلاص متفقين اننا دايمًا هنخزن التاريخ والوقت بصيغة ال UTC في ال Database ولكن عند تحويل الصيغة لل Local Time Zone ممكن تقابلنا مشكلة التوقيت الصيفي و لذلك لازم المكتبة تكون بتدعم تغييرات التوقيت الصيفي لمنع حدوث أخطاء نتيجة تغيير الساعة.

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
