
VOL35: Top 6 Deployment Strategies
أهلًا وسهلا بكم في العدد الخامس والثلاثين من النشرة الأسبوعية لاقرأ-تِك 🎉


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد الخامس والثلاثين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية, من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة, ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

TOP 6 Deployment Strategies
Mixtral AI - Mixture of Experts
Database Cheatsheet for System Design
Optimizing SQL Queries Using Rank Function Row_Number
Apache Airflow XCOMs - Sharing Information Between Tasks
ستجدون أيضًا في هذه النشرة:
الشراكات - Sponsorship
قناة التليجرام مجانية للجميع حتى يصلك كل مقال جديد
كيفية كتابة مقالات معنا في اقرأ-تِك: والمقالات تكون متاحة ومجانية للجميع ومحفوظة باسم الكاتب بكل تأكيد
كيفية الاشتراك في اقرأ-تِك من خلال InstaPay و VodafoneCash
TOP 6 Deployment Strategies
لما نيجي نتكلم عن الـ Deployment Strategies اللي بتستخدمها الشركات الكبيرة، الهدف الأساسي بيبقى إننا ننقل التحديثات الجديدة للـ Production Environment بأقل تأثير سلبي ممكن على المستخدمين.
فورقة وقلم وخلونا نستعرض الأنواع المختلفة من الاستراتيجيات دي مع مميزات وعيوب كل واحدة فيهم 🚀

Blue-Green Deployment
في الاستراتيجية دي بيبقى عندنا بيئتين شغالين في نفس الوقت: بيئة قديمة بتبقى هي دي الـ (Blue) وبيئة جديدة بتكون هي دي الـ (Green).
أول ما التحديث الجديد يبقى جاهز، بنحول الـ Traffic من بيئة الـ Blue للـ Green مرة واحدة. فيبدأ الناس بدل ما كانت بتروح للـ Blue Deployment تروح للـ Green وهنا بنتكلم طبعًا عن Real Traffic اتعمله Routing باستعمال Load Balancer للـ Green Deployments.
مميزات الـ Blue-Green Deployment:
تقليل الـ Downtime لأن الـ Traffic بيتحول بالكامل مرة واحدة.
لو حصلت مشكلة، الرجوع للبيئة القديمة بيبقى سهل وسريع لإن احنا لسه عندنا الـ Blue Environment لسه موجودة.
عيوب الـ Blue-Green Deployment:
محتاج موارد زيادة لإن بيئتين لازم يكونوا شغالين في نفس الوقت مع بعض.
مثال على ده: شركات كتيرة زي Amazon وغيرها بتستخدم الـ Blue-Green Deployment عشان تحافظ على استمرارية الخدمات بدون تأثير على المستخدمين وعشان يبقى سهل بالنسبالهم يرجعوا للبيئة القديمة لو حصل أي مشاكل غير متوقعة.
Canary Deployment
الاستراتيجية دي بتعتمد على إننا ننقل التحديث بشكل تدريجي يعني Gradually لعدد محدود من المستخدمين الأول، ولو الأمور مشيت كويس، نكمل تعميم التحديث لباقي المستخدمين.
وليكن هنعمل Apply على التحديث الجديد لـ 20% من الـ Machines اللي عندنا و 80% هيفضلوا لسه محافظين على النسخة القديمة وبالتالي الناس لما يطلبوا الخدمة 20% منهم هيروح للجديد و 80% هيفضلوا لسه بيجيلهم النسخة القديمة والنسبة دي طبعا احنا بنتحكم فيها على حسب احتياجاتنا.
مميزات الـ Canary Deployment:
لو فيه أي مشاكل، بتأثر على عدد محدود من المستخدمين بس.
بتساعد في اختبار التحديث الجديد في البيئة الحقيقية.
عيوب الـ Canary Deployment:
محتاجين Monitoring دقيق عشان نعرف إذا كان فيه مشاكل بسرعة.
مثال: شركات زي Google و Netflix بتستخدم Canary Deployment عشان تجرب الـ Features الجديدة قبل تعميمها على كل المستخدمين وبالتالي يكون فيه نسبة بس بيجيلهم التحديث الجديد ونسبة تانية لسه بيظهرلهم النسخة القديمة.
Rolling Deployment
في الـ Rolling Deployment، التحديث بيتنقل بشكل تدريجي لمجموعة من السيرفرات بدلاً من نقل التحديث بالكامل مرة واحدة.
فلو عندنا مثلا 10 Servers هيبدأ يتعمله Apply على واحد تلو الآخر بشكل تدريجي لحد مايتم على كل الأجهزة والـ Servers اللي موجودة.
مميزات الـ Rolling Deployment:
الـ Downtime قليل جداً لإن السيرفرات بتتحدث واحدة واحدة.
بيقلل المخاطرة لأن التحديث بيكون بشكل تدريجي.
عيوب الـ Rolling Deployment:
لو حصلت مشكلة، صعب ترجّع التحديث لكل السيرفرات بشكل سريع وده لإن احنا محتاجين نـ Rollback كل جهاز بشكل تدريجي ونرجع للنسخة القديمة فهياخد وقت.
مثال: فيه شركات بتفضل تستخدم الـ Rolling Deployment عشان تتجنب المشاكل الناتجة عن تحديث كل السيرفرات مرة واحدة فيبقى الموضوع ماشي واحدة واحدة وبشكل تدريجي.
Mixtral AI - Mixture of Experts
بعد انتشار الأقاويل بأن GPT-4 يعتمد على عدة نماذج تعمل معًا لإنتاج مخرجاته، ظهر مصطلح "Mixture of Experts" واختصاره (MOE). هذه المنهجية تعتمد على تجميع مجموعة من النماذج الصغيرة (Experts)، حيث يتخصص كل منها في معالجة مهام معينة.
الفكرة تشبه استشارة مجموعة من الخبراء المتخصصين في مجالات متعددة بدلاً من الاعتماد على خبير واحد شامل، مما يؤدي إلى تحسين دقة وفعالية الأداء.
في هذا المقال، سنتناول آلية عمل MoE، مميزاته، واستعراض نموذج Mixtral من شركة Mistral AI الذي يطبق هذا المفهوم.
ما هو Mixture of Experts (MoE)
الMixture of Experts هو ببساطة مجموعة من الmodels، حيث يُطلق على كل نموذج "خبير" (expert) ومع الوقت كل expert بيكون مسؤول عن حاجه معينه. يمكن تشبيه هذا بنظام يجمع خبراء متخصصين في مجالات متعددة لمناقشة موضوع معين. بدلاً من الاعتماد على خبير شامل لمناقشه الموضوع معه وحده، لذلك الأفضل أن نستعين بمجموعة من الخبراء المتخصصين لتحقيق أفضل النتائج.
عناصر تكوين Mixture of Experts (MoE)
يتكون MoE من عنصرين رئيسيين:
Sparse Layers: تُستخدم بدلاً من FFN layers و تحتوي على عدد معين من experts (مثلًا experts 8)، ويمثل كل expert شبكة FFN، لكن يمكن أن تكون أيضًا شبكات أكثر تعقيدًا أو حتى نموذج MoE بنفسه، مما يؤدي إلى إنشاء نماذج MoE هرمية.
Gate Network أو Router: والتي تحدد أي الtokens تُرسل إلى أي expert. كما سنستكشف لاحقًا، يمكننا إرسال توكن إلى أكثر من expert واحد. ويعتمد تدريب الـ Router على توجيه الtokens بشكل فعال إلى ال experts المناسبين.
شركة Mixtral ونموذج Mistral AI
ظهرت شركة Mistral AI على الساحة بتقديم نموذجها Mixtral 7B، الذي تمكن من منافسة نماذج كبيرة مثل LLAMA2. ثم أطلقت الشركة نموذجًا أكثر تطورًا، Mixtral 8x7B، الذي يعتمد على 8 خبراء، كل خبير بحجم7B parameters وأظهر Mixtral 8x7B أداءً أفضل في عدة مهام، خصوصًا في التعامل مع لغات متعددة، بينما كان LLAMA 70B يعتمد بشكل أساسي على اللغات اللاتينية.
أيهما أفضل التدريب بين النماذج الكبيرة والصغيرة ؟
عند اتخاذ القرار بين تدريب نموذج كبير لعدد محدود من الفترات الزمنية (epochs) أو تدريب نموذج صغير لفترات زمنية أطول، يعتمد الأمر على الأولويات والموارد المتاحة.
لنفرض أن هناك ميزانية ثابتة. هل يتم تدريب نموذج كبير (large model) على 10 epochs ، أو نموذج صغير (small model) على 100 100 epochs ؟
النماذج الكبيرة لديها القدرة على التعلم بشكل أسرع وأعمق، حتى لو تم تدريبها لعدد أقل من ال epochs، مما يعطيها ميزة في مرحلة ال fine-tuning. ولكن عند الانتقال إلى الإنتاج(production) ، تظهر تحديات في الأداء وسرعة التنفيذ، حيث يمكن أن تكون النماذج الصغيرة أسرع وأقل تكلفة.
إذا كانت الأولوية هي دقة النموذج يمكن أن يكون الlarge model هو الخيار الأفضل، حتى مع عدد أقل من ال epochs
إذا كانت الأولوية هي سرعة التنفيذ (inference) والكفاءة في الإنتاج (production) ، فإن الsmall model قد يكون أكثر ملاءمة، خاصة في التطبيقات التي تتطلب أداءً سريعًا وتكلفة تشغيل منخفضة.
النماذج الكثيفة مقابل النماذج المتناثرة Dense vs. Sparse Models
الفروقات الأساسية بين Dense و Sparse تتعلق بكيفية استخدام ال nodes أثناء التدريب (training) والتنفيذ(Inference)
 | Download Scientific Diagram")
مثال للايضاح:
إذا كان لدي مثلاً 100 خانة لأضع فيها جميعا أرقاماً، حيث تكون جميع الخانات مشغولة هنا يمكن القول إن النموذج مكثف (Dense)
لكن إذا كان لدي 100 خانة، وليست جميعها مشغولة، بمعنى أن هناك بعض الخانات تحتوي على قيمة صفر، في هذه الحالة نسميه نموذج نادر (Sparse). ومع ذلك، فإن الشبكة العصبية لا تحتوي على قيم صفر، بل دائماً تحتوي على قيم، حتى وإن كانت ضعيفة أو صغيرة.
إذا افترضت أنك قادر على بناء نموذج يحتوي على 100 مليار معلومة (parameters)، وإذا قمت ببنائه على هيئة كتلة واحدة، هنا تتحدث عن شبكة عصبية مكثفة (Dense NN). لكن إذا تمكنت من تقسيم الـ 100 مليار parameters إلى مجموعات تتكون كل منها من 10 مليارات، وفي أثناء التدريب تقوم بتشغيل مجموعة واحدة فقط من ال parameter وليس جميعها، هنا قد أنشأت نموذجاً نادراً (Sparse Model).
وبالرغم من أنك تمتلك 100 مليار معلمة، إلا أنك تتحكم في تشغيل 10 مليارات فقط في وقت التنفيذ (inference) لذا، لدينا نموذج كبير، لكن في وقت التنفيذ ، جزء منه فقط هو الذي يعمل، وبالتالي ينطبق عليه مصطلح (sparse)

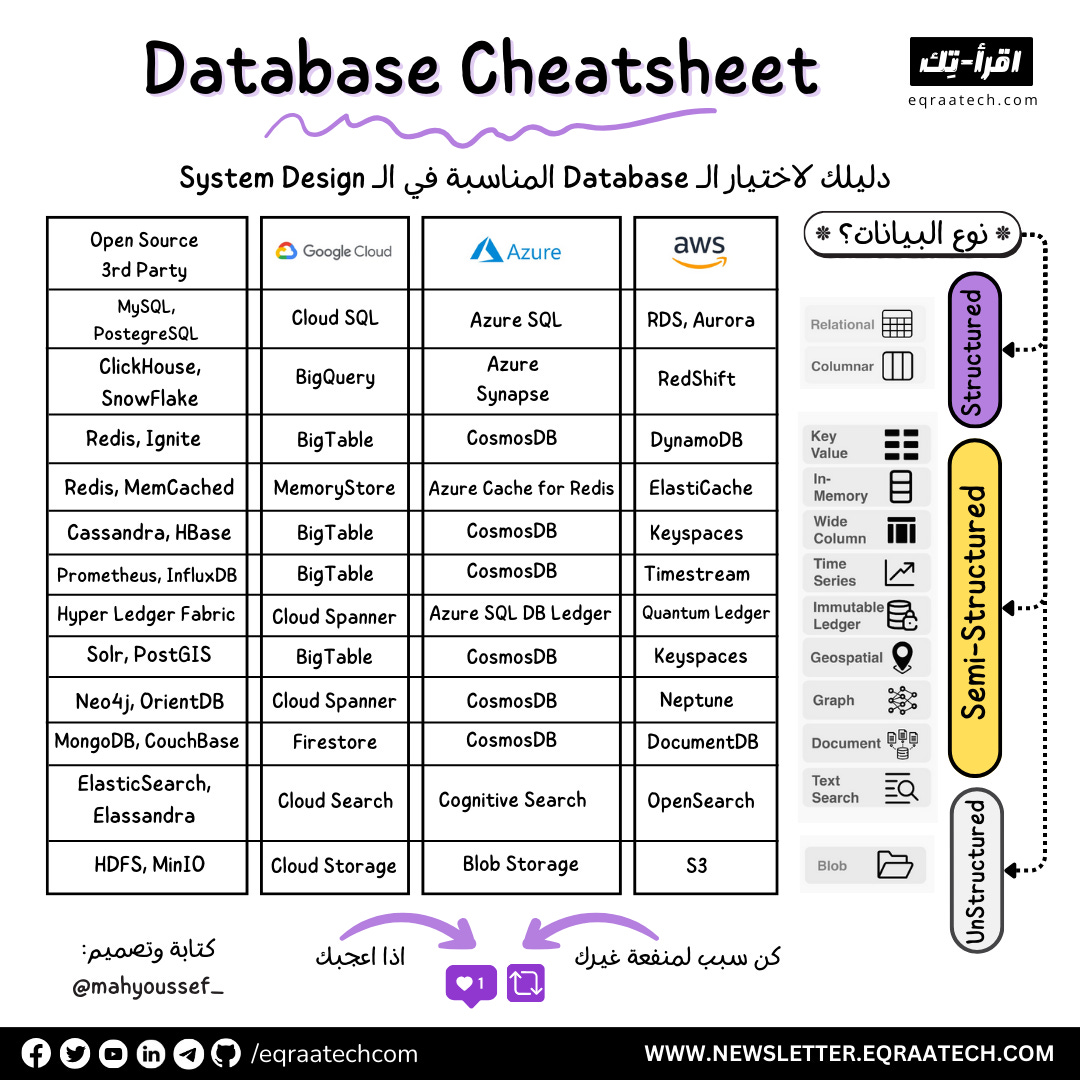
Database Cheatsheet For System Design
لازم نكون عارفين ان اختيارنا للـ Database في الـ System اللي بنبنيه، هو قرار مش سهل وقرار هنبقى ملزمين بيه لفترة طويلة فلازم نختارها بعناية خصوصًا لو كمان الموضوع هيتضمن Budget وفلوس هتندفع.
عشان نسهل على نفسنا الاختيار هنحاول الأول نجاوب على السؤال ده:
هو ايه نوع الـ Data اللي محتاجين نخزنها في الـ System ؟
والاجابة هتكون حاجة من 3 واللي هنحاول سوا نبني Mind-Map في عقلنا عشان نسهل الاختيار علينا شوية:
Structured Data (Standard SQL Table Schema)
Semi-Structured Data (JSON, XML, etc..)
UnStructured Data (Blob)
بعد معرفتنا بنوع البيانات اللي هنخزنها، هنكون محتاجين نعرف حاجتين اتنين بس:
ايه هي الـ Use-Case أو هدفنا من تخزين البيانات
هل هنروح ناحية الـ Cloud ولا هيبقى اعتمادنا على الـ Open-Source والـ 3rd Party ؟
وده لإن تحديد الهدف من التخزين هيفرق في اختيار الـ Database وهيخلينا نروح لنطاق أقل من الاختيار، واعتمادنا على الـ Cloud من عدمه كذلك هيسهل علينا الاختيار وهيضيق نطاق الاختيار.
الشراكات - Sponsorship
بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship وتقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 🚀
لا تدع شيء يفوتك!

بفضل الله قمنا بإطلاق قناة اقرأ-تِك على التليجرام مجانًا للجميع 🚀
آملين بده اننا نفتح باب تاني لتحقيق رؤيتنا نحو إثراء المحتوى التقني باللغة العربية ، ومساعدة لكل متابعينا في انهم يوصلوا لجميع أخبار اقرأ-تِك من حيث المقالات ومحتوى ورقة وقلم والنشرة الأسبوعية وكل جديد بطريقة سريعة وسهلة
مستنينكوا تنورونا , وده رابط القناة 👇
Optimizing SQL Queries Using Rank Function Row_Number
Rank Function in SQL
أولا يعني ايه كلمة Rank ؟
كلمة "rank" بالإنجليزية معناها "ترتيب" أو "رتبة". في السياق العام، تستخدم للإشارة إلى موضع أو مستوى شيء معين ضمن مجموعة.
في عالم البيانات وSQL، تعني "Rank" تحديد موضع كل صف بناءً على قيمة معينة. مثلاً، لما نقول إن "الشخص X لديه رتبته 1 في المبيعات"، يعني إنه الأفضل في مجموعة معينة بناءً على مبيعاته يعني تصنيفه بين زملائة اللي شغاليين معاه في المبيعات نفس الشغلانه هو الاول بينهم.
ببساطة، "Rank" بتدل على كيفية تصنيف شيء بالنسبة لآخرين.
في الـ SQL في 4 انواع للـ Ranking Functions تعالو نتعرف عليهم:
RANK()
DENSE_RANK()
ROW_NUMBER()
NTILE()
وقبل مانتعرف عليهم واحد واحد تعالو الاول نتخيل مجوعة من الداتا عشان نطبق عليها الأنواع الأربعة من الـ Ranking Functions ، فمثلا تخيل ياصديقي أن الداتا هي درجات الطلاب في ثلاث مواد دراسية : (رياضيات وكيمياء وتاريخ).

لو انا عاوز اصنف او ارتب او اعمل Rank للطلاب بناء على المجموع الكلي الـ Total Score فعاوز أعرف مين الطالب اللي طلع الأول ومين التاني وهكذا ... نعمل كده ازاي ؟
وقبل أي حاجة .. ازاي اصلا نحسب المجموع الكلي لكل طالب ؟
بكل سهولة عندنا الـ Sum Function بتقدر تعمل كده تعالو نشوف ..
SELECT student_id, SUM(final_score) AS total_score FROM dfحيث الـ df هو اسم الـ Dataset أو الجدول بتاعنا وبكده نكون قدرنا نجمع درجات كل طالب والنتيجة هتبقة كده:

تمام انت كده قدرت تجيب المجموع النهائي لكل طالب عاوزين بقى نصنفهم ونعمل Ranking ونعرف مين الاول والتاني ، وده كان ممكن نعمله من الأول في خطوه و Query واحدة.
Apache Airflow XCOMs - Sharing Information Between Tasks
كـ Data Engineers، مش بس مهمتنا أننا نطور أو نحافظ على الـ Data Pipelines من أي مشاكل ممكن تحصل فيها، لأ ده كمان من ضمن مهامنا الأساسية أننا نقدر نخليها تتنفذ بشكل دوري دون أي تدخل مننا.
ومن أشهر الـ Tools المستخدمة لفكرة الـ Automation دي هي Apache Airflow ، وهي أداة مفتوحة المصدر "Open-Source Tool" نقدر من خلالها أننا نحدد وقت معين لتنفيذ الـ Pipelines، ونراقب حالتها ونفهم سبب المشاكل في حالة حدوثها، وكمان نقدر بسهولة نحدد الاعتمادية أو الـ Dependencies بتاعة أجزاء الـ Pipelines المختلفة على بعضها البعض.
زي أن يكون فيه جزء من الـ Pipeline ماينفعش يتنفذ غير لما جزء أو مجموعة أجزاء تانية تتنفذ الأول ، وكمان من خلاله نقدر نخلي جزء من الـ Pipeline يتنفذ أول ما حدث معين يحصل ، وكتير من العمليات اللي ممكن ننفذها من خلال Apache Airflow.
Apache Airflow
الـ Apache Airflow بيقوم على مبدأ مهم جدًا وهو الـ DAGs أو الـ Direct Acyclic Graphs.
وهي عبارة عن طريقة معينة لتنظيم أجزاء الـ pipeline الواحد واللي بتُسمَى Tasks ، فكل Task بينفذ مهمة معينة زي أنه يقرأ من database، يعمل data cleaning، ينفذ spark job، أو يكتب file على HDFS.
كل Task من دول بيشارك في الـ pipeline علشان في الآخر نحصل على النتايج اللي محتاجينها، وكل Task من دول ممكن جدًا يبقى شرط من شروط تنفيذه هو تنفيذ Task تاني معين قبله، وتنفيذه بنجاح كمان.
وممكن برضه يبقى فيه Task منهم مستنية معلومة من Task تانية قبلها علشان تستخدمها في العملية اللي هتعملها على الـ data.
Sharing Information Between Tasks
فكرة مشاركة المعلومات ما بين الـ Tasks وبعضها فكرة مهمة جدًا لإن المعلومات دي ممكن تبقى Lookup data ناتجة عن Task هحتاجها في Task بعدها، وممكن يبقى Timestamp بيعبر عن الوقت اللي اتنفذت فيه الـ Task دي ومهم باقي الـ Tasks تبقى واعية بالقيمة دي.
ممكن برضه تبقى parameters زي مكان file معين أو اسمه ومحتاجاه علشان أعمل عليه عمليات تانية في Tasks قادمة، وأمثلة وuse cases كتير جدًا ممكن نحتاج فيها نشارك معلومات زي دي.
فـ Apache Airflow بيقدم مجموعة من الحلول لمشكلة زي دي ومنها الـ Variables والـ XCOMs ، والإتنين هما طرق علشان نخزن المعلومات اللي محتاجين ننشرها من Task في مكانٍ ما، وتقدر أي Task تانية تستخدم المعلومة دي من خلال أنها تقراها فقط من المكان ده.
وفي المقال ده هنتكلم عن الXCOMs، هنعرف معناها، بتخزن المعلومات دي ازاي ؟ وازاي نقدر نحصل على المعلومات دي، وفي النهاية هنوضح بمثال كامل ازاي مشاركة المعلومات بتتم بين الـ Tasks وبعضها.
XCOMs
الـ XCOM هي اختصار لـ cross-communication، وهو بالظبط المبدأ اللي بندور عليه علشان يبقى فيه طريقة تواصل بين الـ Tasks وبعضها ، فأي Task يقدر بإستخدام الـ XCOM أنه يشارك بمعلومة، أو يقرأ معلومة كان بالفعل فيه Task تاني قام بمشاركتها قبل كده.
المعلومات اللي الـ Tasks بتشاركها بتكون متخزنة في الـ Metadata Database الخاصة بـ Airflow، فَبالتالي أي Task في الـ DAG أو حتى أي DAG تاني يقدر يقرأ المعلومات دي.
طيب ازاي نقدر نشارك أو نقرأ المعلومات دي ؟ عن طريق 2 Functions:
مشاركة المعلومة عن طريق
()xcom_pushواللي بتاخد 2 parameters أساسية وهي الـ key والـ value ، والـ key بيكون قيمة unique لكل value بيتم مشاركتها عن طريق الـ XCOM، والـ value هي القيمة اللي محتاجين نشاركها نفسها.
xcom_push(key="random_number", value=number)قراءة المعلومة عن طريق
()xcom_pullواللي برضه بتاخد 2 parameters أساسية وهي الـ key المرتبط بالـ value اللي محتاجي نقراها، والـ Task ID بتاع الـ Task اللي شارك المعلومة دي.
xcom_pull(key="random_number", task_ids="generate_random_number")
تقدروا دلوقتي تشتركوا في اقرأ-تِك بخصم الـ 20% وتنضموا لمجتمع مهتم بالقراءة في هندسة البرمجيات بـ 50 جنيه بس 🎉
وتستمتعوا بحرية كاملة في قراءة المقالات في مواضيع مختلفة بجودة عالية زي:
Data Structure & Algorithms , System Design , Distributed Systems , Micro-Services, Clean Code, Refactoring, Databases , Web Development, DevOps وغيرهم كتير باللغة العربية!
بالاضافة لمحتوى ورقة وقلم اللي بنشرح فيه مفاهيم برمجية بطريقة سهلة وباستعمال صور توضيحية 🚀
ولو فيه مشاكل في الدفع الأونلاين فمتاح دلوقتي الاشتراك من خلال InstaPay و VodafoneCash 💪
تقدروا تتواصلوا معانا من خلال الـ WhatsApp Business أو من خلال الرسايل على مواقع التواصل الاجتماعي أو من خلال البريد الالكتروني contact@eqraatech.com 😍

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
