
VOL30: How Discord Stores Trillions of Messages
أهلًا وسهلا بكم في العدد الثلاثين من النشرة الأسبوعية لاقرأ-تِك 🎉


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد الثلاثين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية, من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة, ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

How Discord Stores Trillions of Messages
Top 24 System Design Terminologies
The Exploratory Data Analysis (EDA) Magic Funnel
How to Store Passwords In Database
Cloud Computing Models In a Nutshell
ستجدون أيضًا في هذه النشرة:
الشراكات - Sponsorship
قناة التليجرام مجانية للجميع حتى يصلك كل مقال جديد
كيفية كتابة مقالات معنا في اقرأ-تِك: والمقالات تكون متاحة ومجانية للجميع ومحفوظة باسم الكاتب بكل تأكيد
كيفية الاشتراك في اقرأ-تِك من خلال InstaPay و VodafoneCash
How Discord Stores Trillions of Messages
في سنة 2017 فريق المهندسين في Discord نشروا مقال عن إزاي بيخزنوا مليارات الرسايل. وقتها شاركوا الرحلة بتاعتهم من حيث استخدام MongoDB لحد ما قرروا ينقلوا بياناتهم لـ Cassandra، وده لإنهم كانوا بيدوروا على قاعدة بيانات قابلة للتوسيع Scalable، بتتحمل الأخطاء Fault-Tolerant، وما تحتاجش صيانة كتير Maintenance.
ولإنهم كانوا عاوزين قاعدة البيانات تكبر معاهم، كانوا متأملين إن احتياجات الصيانة ما تكبرش بنفس معدل النمو بتاع التخزين. ولكن للأسف، ده ما كانش الحال - فمجموعة Cassandra بتاعتهم بدأت تظهر فيها مشاكل في الأداء كبيرة وكانت بتحتاج مجهود كبير عشان يحافظوا عليها، مش عشان يطوروها.
وبعد حوالي 6 سنين، اتغيرت حاجات كتير، والطريقة اللي بيخزنوا بيها الرسايل كمان اتغيرت.
Cassandra Troubles
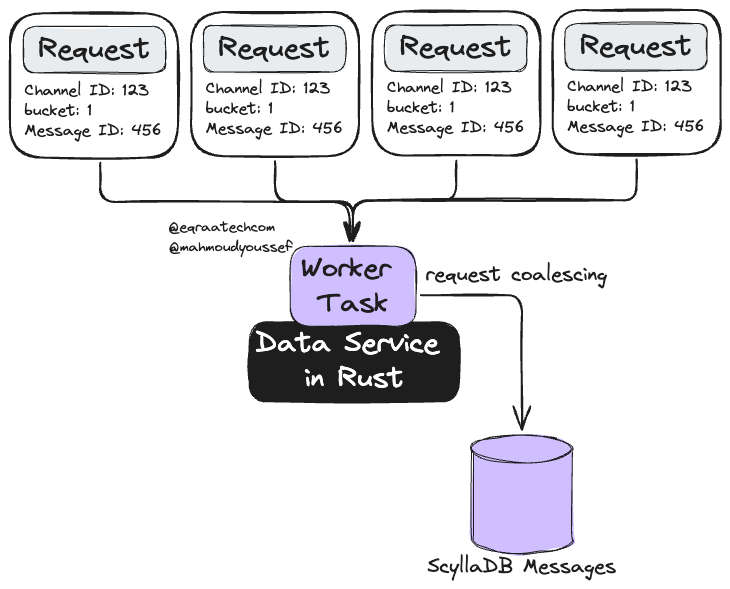
فريق المهندسين في Discord كانوا بيخزنوا الرسايل في قاعدة بيانات اسمها cassandra-messages. وزي ما الاسم موضح، كانت شغالة بـ Cassandra وبتخزن الرسايل. في 2017، كانوا مشغلين تقريبًا حوالي 12 node لـ Cassandra، وكان عندهم مليارات الرسايل.
اما في بداية 2022، عدد الـ nodes زاد ووصل لـ 177 وعدد الرسايل بقى بالـ trillions. وللأسف، النظام ده كان بيحتاج صيانة كتير جدًا — والفريق اللي على الـ on-call كان بيتبعت له تحذيرات كتير عن مشاكل في الـ database، والـ latency كان غير متوقع إطلاقًا، وكانوا مضطرين يوقفعوا عمليات الصيانة لأنها كانت بتاخد وقت ومجهود كبير من الفرق.
إيه اللي كان مسبب المشاكل دي؟ خلينا نبص على الرسالة نفسها.
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);الـ CQL statement اللي فوق هو نسخة مبسطة من الـ schema بتاعت الرسايل. كل الـ IDs اللي بيستخدموها هي عبارة عن Snowflake، ودي Service من Twitter عشان تـ Generate IDs فبالتالي ده بيخليها sortable بشكل زمني.
وبيعملوا partition للرسايل على حسب الـ channel اللي اتبعتت فيه، بالإضافة للـ bucket، اللي هو عبارة عن Window كده زمنية ثابتة. الـ partitioning ده بيخلي كل الرسائل اللي في channel و bucket معينين تتخزن مع بعض وتكون مكررة على 3 nodes (أو حسب الـ replication factor اللي متظبط).
لكن جوه الـ partitioning ده في مشكلة محتملة في الأداء الا وهي: السيرفر اللي فيه عدد قليل من الأعضاء بيبعت رسائل أقل بكتير جدًا مقارنة بالسيرفر اللي فيه مئات الآلاف من الناس. طب ده هيعمل مشكلة في ايه ؟ خلونا نكمل ..
في Cassandra، الـ reads بتكون تقيلة شويتين وHeavier من الـ writes. وده لإن الـ writes اصلًا بتتضاف في الـ commit log وبتتكتب بعد كده في structure موجود في الـ memory اسمه memtable اللي بعد كده بيتحفظ على الـ disk ويتعمله Flushing.
أما الـ reads، فهي بتحتاج تقرا من الـ memtable وكمان ممكن تحتاج تقرا من كذا SSTable (ملفات موجودة على الـ disk)، ودي بتكون عملية تقيلة شويتين. فالـ reads الكتير اللي بتحصل في نفس الوقت مع تفاعل المستخدمين مع السيرفرات بتسبب حاجة بنسميها "hot partition" وهي دي المشكلة اللي بتنتج من الـ Partition بناء على الـ Channel. وحجم الـ dataset بتاعة Discord، مع نمط التفاعل ده، عمل مشاكل في الـ cluster ككل.
فلما كانوا بيقابلوا hot partition، ده كان بيأثر على الـ latency في الـ cluster كله. ولما الـ node بتاخد وقت أطول عشان تخدم الـ Traffic، كل الـ queries التانية اللي رايحة للـ node كانت بتعاني من نفس التأخير، وده لإنهم كانوا شغالين بالـ Quorum Consistency Level وده كان بيزود تأثير المشكلة على المستخدمين بالتأكيد.
كمان مهام الصيانة كانت بتعمل مشاكل كتير جدًا. فكانوا دايمًا متأخرين في عملية الـ compactions، اللي فيها Cassandra بتدمج الـ SSTables على الـ disk علشان تحسن أداء الـ reads. وده كان بيخلي الـ reads تقيلة، وكانوا بيشوفوا تأخير أكبر لما الـ node كانت بتحاول تعمل compact.
بالإضافة لإنهم كانوا بيعملوا عملية اسمها "gossip dance"، اللي فيها بنخرج الـ node من الـ rotation علشان نديها فرصة تعمل compact من غير أي Traffic تستقبله، وبعدين يرجعوها تاني علشان تلتقط الـ hints من hinted handoff، ويكرروا العملية لحد ما الـ backlog بتاع الـ compaction يخلص.
وكانوا بيقضوا وقت طويل برضه في تعديل إعدادات الـ JVM's garbage collector والـ heap settings، لأن الـ GC pauses كانت بتسبب ارتفاع كبير في الـ latency.
Changing Architecture
مجموعة الرسايل ما كانتش هي الـ Cassandra cluster الوحيدة اللي Discord بيشتغل عليها بالتأكيد. وكان فيه أكتر من cluster تاني، وكلهم كانوا بيعانوا من مشاكل مشابهة (ولو إن كانت مشاكل الرسايل هي الأصعب بالنسبالهم).
في المقال اللي نشروه قبل كده، اتكلموا عن إنهم كانوا مهتمين بـ ScyllaDB، وهي Database متوافقة مع Cassandra مكتوبة بلغة C++. والوعود بتاعتها كانت بتقول إنها أسرع، بتصلح المشاكل بشكل أسرع، وعندهاعزل أفضل للـ workload بسبب الـ shard-per-core architecture بتاعتها، وما فيش فيها مشكلة الـ garbage collection.
ورغم إن ScyllaDB مش خالية من المشاكل، بس هي خالية من الـ garbage collector، لأنها مكتوبة بـ C++ بدل الـ Java. وتاريخيًا، فريق مهندسين Discord كان بيعاني مع الـ garbage collector في Cassandra، من الـ pauses اللي بتأثر على الـ latency، لحد pauses طويلة جدًا كانت بتوصل لدرجة إن لازم شخص من الفريق يعيد تشغيل الـ node ويهتم بيها بشكل يدوي.
المشاكل دي كانت سبب كبير في الـ on-call، وجذور كتير من المشاكل اللي كنا بنواجهها في stability.
فبعد ما جربوا ScyllaDB وشافوا تحسينات، قرروا ينقلوا كل قواعد البيانات بتاعتهم ليها. وبالرغم إن القرار ده ممكن يكون في مقال تاني لوحده منفصل خالص، فباختصار في 2020 كانوا نقلوا تقريبًا كل قواعد البيانات ما عدا واحدة لـ ScyllaDB.
والـ database اللي كانوا لسه ما قاموش بنقلها هي: cassandra-messages.
Top 24 System Design Terminologies
تعالوا نشوف مع بعض شوية من أهم المصطلحات المستخدمة في تصميم الأنظمة والـ (System Design) في مجال هندسة البرمجيات باللغة العربية ، مع شرح مبسط لكل مصطلح 🎉
الـ Scalability: هي قدرة النظام إنه يكبر ويستوعب عدد أكبر من المستخدمين أو البيانات من غير ما يتأثر الأداء.
الـ Load Balancer: جهاز أو برنامج بيقوم بتوزيع الأحمال على عدة سيرفرات بحيث ميكنش في ضغط على سيرفر معين.
الـ Sharding: تقسيم قاعدة البيانات الكبيرة لعدة أجزاء أصغر على عدة سيرفرات عشان نحسن الأداء.
الـ Cache: تخزين بيانات مؤقتًا في مكان قريب من المستخدم عشان الوصول ليها يكون أسرع.
الـ Latency: الوقت اللي بياخده النظام عشان يستجيب لطلب معين من المستخدم.
الـ Throughput: كمية البيانات اللي يقدر النظام يعالجها أو ينقلها في فترة زمنية معينة.
الـ Redundancy: وجود نسخ احتياطية من البيانات أو الأنظمة لتجنب الفشل في حالة حدوث مشكلة.
الـ Replication: نسخ البيانات عبر عدة مواقع أو سيرفرات عشان نحافظ عليها في حالة فشل أحدهم.
الـ Load Shedding: طريقة لتخفيف الحمل عن النظام في أوقات الضغط العالي بتجاهل طلبات أقل أهمية.
الـ Fault Tolerance: قدرة النظام على الاستمرار في العمل حتى لو حصلت مشكلة في جزء معين.
الـ Consistency: التأكد إن البيانات في النظام متطابقة في كل الأجزاء.
الـ Partitioning: تقسيم البيانات في قاعدة البيانات لأجزاء أصغر للتعامل مع كل جزء بشكل مستقل.

الشراكات - Sponsorship
بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship وتقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 🚀
لا تدع شيء يفوتك!

بفضل الله قمنا بإطلاق قناة اقرأ-تِك على التليجرام مجانًا للجميع 🚀
آملين بده اننا نفتح باب تاني لتحقيق رؤيتنا نحو إثراء المحتوى التقني باللغة العربية ، ومساعدة لكل متابعينا في انهم يوصلوا لجميع أخبار اقرأ-تِك من حيث المقالات ومحتوى ورقة وقلم والنشرة الأسبوعية وكل جديد بطريقة سريعة وسهلة
مستنينكوا تنورونا , وده رابط القناة 👇
The Exploratory Data Analysis (EDA) Magic Funnel
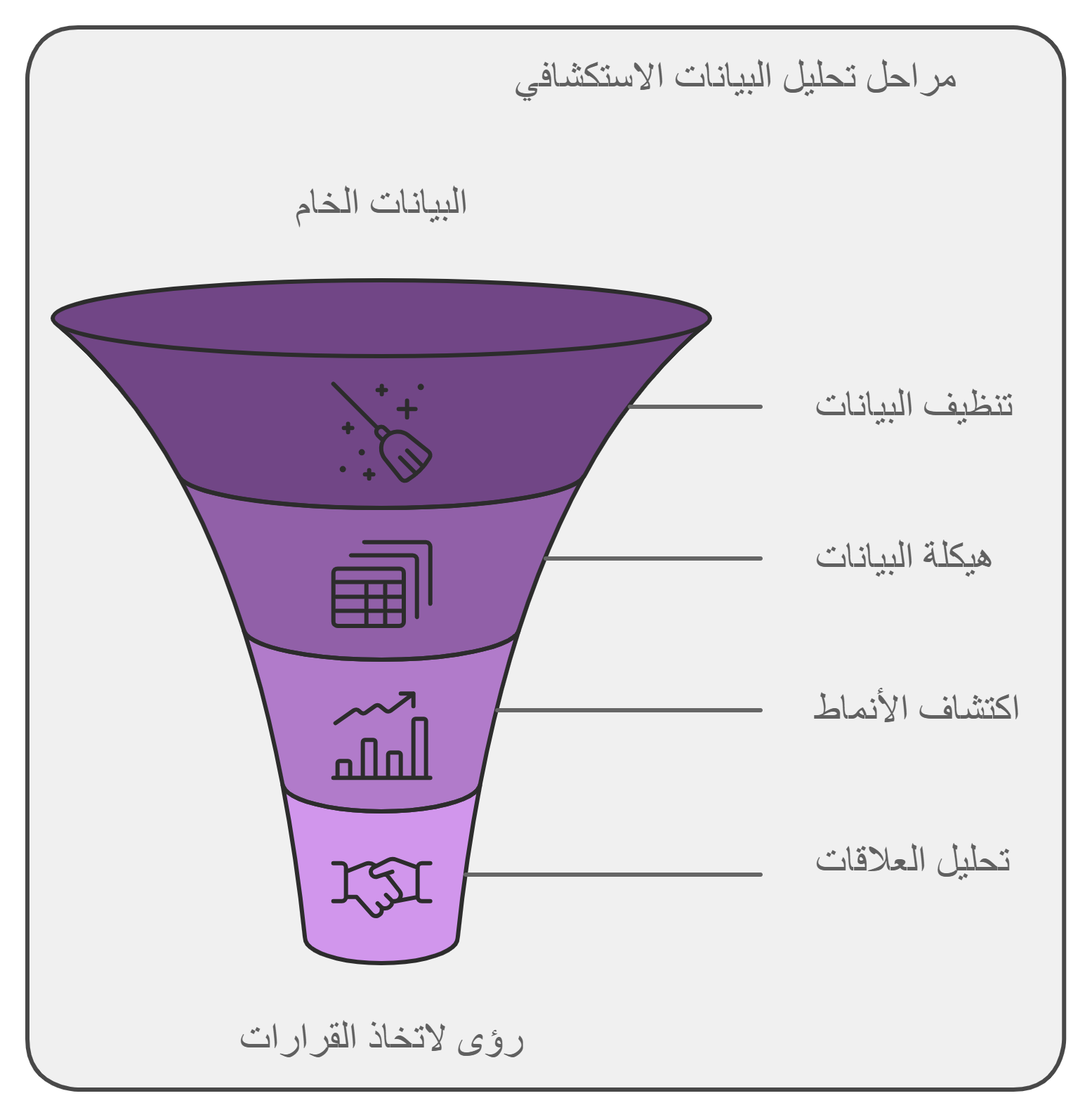
التحليل الاستكشافي للبيانات (EDA)، هو بالضبط زي القمع اللي بتدخله البيانات الخام ، االلي بتبقى عشوائية وقد تبدو بدون معنى عشان يطلعلك منها الخلاصة اللي بيظهر لك منها رؤى كتيرة مفيدة للمكان اللي أنت فيه، واللي بيكشف لنا القوى الحقيقية الكامنة وراء البيانات دي.
 Magic Funnel")
لو ركزت في كل حاجة حواليك، هتلاقيها عبارة عن بيانات كتيرة منها المفهوم ومنها اللي مش مفهوم وده الجزء الأكبر، لأنه مبيبقاش متاح ليك تحليلها واستكشافها بالعين المجردة. لكن في نفس الوقت لازم تفهمها وتستكشفها بطريقة ما. وفي طريقك لفهمها هتقابل المحطة الأهم وهي محطة التحليل الاستكشافي للبيانات (EDA).
ليه الـ EDA خطوة مهمة؟
قبل ما ناخد جولة في المحطة هوضحلك ليه الـ EDA خطوة مهمة؟
الـ EDA بيساعدك على:
فهم خصائص البيانات: بتقدر تشوف العلاقات بين المتغيرات المختلفة (Correlation) وتفهم الأنماط اللي بينها وكمان تعرف الحاجات اللي بتأثر بشكل كبير على البيانات عندك والحاجات اللي تأثيرها أقل.
اكتشاف القيم الغريبة والمفقودة: ممكن تلاقي في البيانات قيم مش مألوفة أو مش متناسقة مع باقي البيانات (Outliers) أو مثلًا قيم مش محددة ومفقودة (Missing values)، يعني مثلًا قيمة عالية جدًا للمبيعات عندك أو قيمة مش مكتوبة خالص. هنا بتكتشف إن في حاجة غلط ولازم بترجع تشوف سبب الغلط جاي منين وتصلحه.
تحضير البيانات للخطوات المتقدمة: بعد ما استكشفت بياناتك وصلحت أخطائها، بتحتاج تدخلها في تحليل أعمق عشان تفهم كل تفصيلة فيه، وكمان ممكن تدخلها على نماذج للتنبؤ بالمستقبل (Machine Learning Models) واللي كفاءتها بتعتمد على جودة البيانات اللي بتدخلها.
مراحل الـ EDA
من هنا هنبدأ جولتنا بمراحل الـ EDA:
هنا بيأتي الجزء الأكثر متعة واللي بتقدر فيه تشوف البيانات بتاعتك في هيئة أرقام مُبسطة وفي شكل رسومات بيانية واضحة.
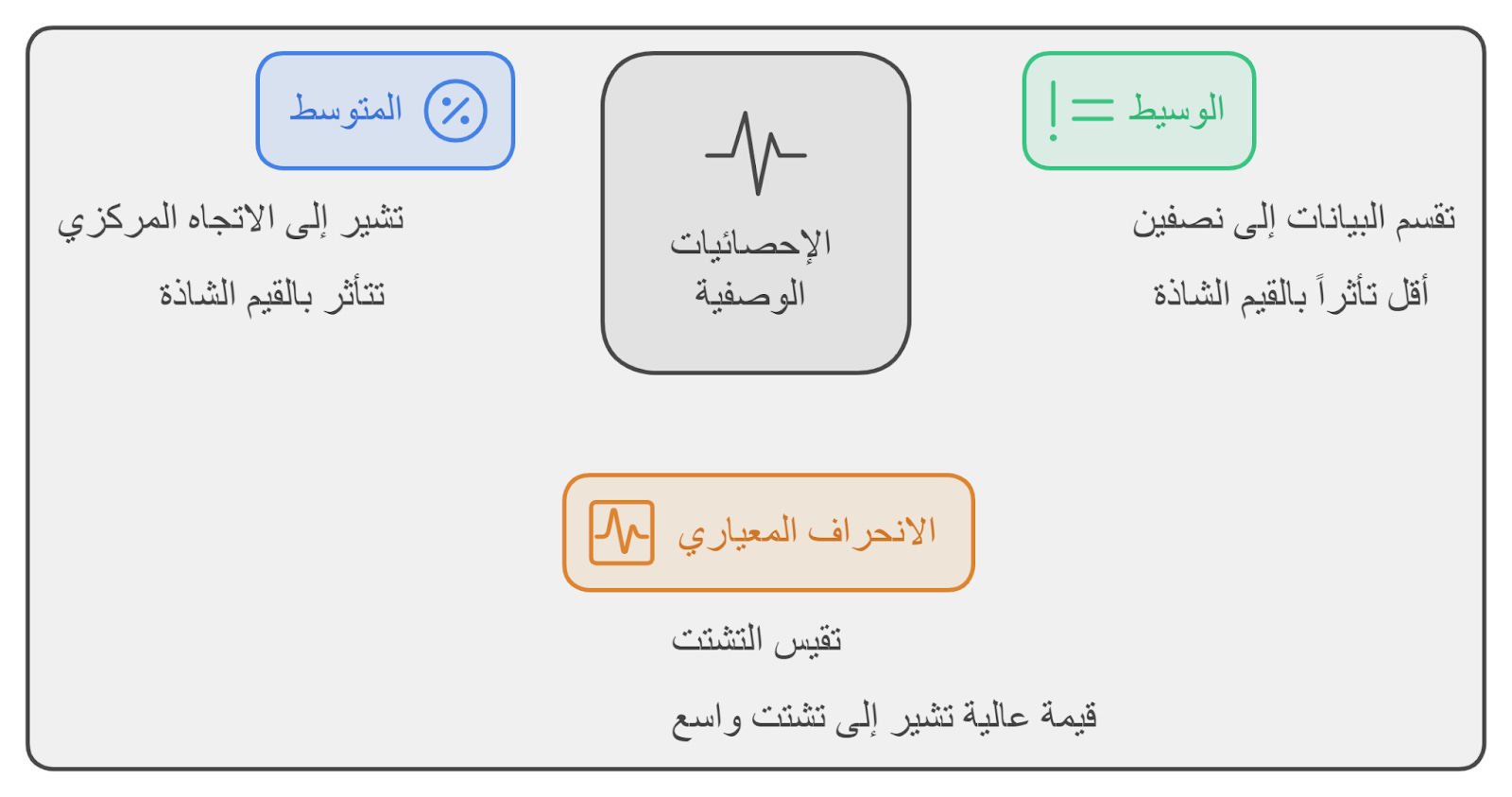
1- الطرق الإحصائية (Statistical methods)
المتوسط (Mean): بنعرف منه القيم اللي بتمثل النصيب الأكبر من البيانات.
الوسيط (Median): وهو القيمة اللي بتقسم البيانات لنصين وبيوضح توزيع البيانات حوالين القيمة دي.
الانحراف المعياري (Standard Deviation): بيقولك البيانات متباعدة عن المتوسط بمقدار قد إيه.
وغيرها كتير من الطرق والمصطلحات الوصفية.
How to Store Passwords In Database
ازاي الـ Passwords بتتخزن في الـ Database وازاي نقدر نتأكد من الـ Password بتاع الـ User سليم وهو بيعمل Login ؟
وقبل ما نبدأ نتكلم عن ده خلونا في البداية نأكد على أهمية الموضوع وأن تخزين الـ Passwords في الـ Database لازم يتم بشكل ميسهلش للـ Hackers أنهم يوصلوا للـ Passwords حتى لو حصل اختراق للـ Database.
طب ايه هي الحاجات اللي بتسهل عملية الوصول للـ Passwords ؟
فيه بعض الحاجات اللي مفروض نبعد عنها تمامًا عشان بتسهل للـ Hackers انهم يوصلوا للـ Passwords زي:
اننا نخزن الـ Passwords كـ Plain Text في الـ Database ، ده هيخلي اي حد Internal شغال في الشركة انه يكون ليه Access على كل الـ Passwords وعارفهم كلهم .. وده برضو هيخلي اختراق الـ Database عملية بتسهل الوصول لكل الـ Passwords اللي موجودة، فالـ Hacker هيكون قدامه الـ Passwords على طبق من ذهب ..
اننا نستعمل Legacy Hashing Algorithms زي الـ MD5 و الـ SHA-1 فبالرغم من انهم يعتبروا Algorithms سريعة جدًا، إلا أنهم يعتبروا Not Secured وسهل يتم معرفة الـ Passwords من خلالهم

طب ازاي نخزن الـ Passwords بشكل آمن ؟
وفقًا لمشروع الـ OWASP واللي هو اختصار لـ Open Web Application Security Project فهم ادونا شوية Guidelines نقدر نمشي عليها عشان نخزن الـ Passwords بشكل آمن زي:
اول حاجة اننا نستعمل Modern Hashing Algorithms والـ Hashing هنا هو عبارة عن طريق واحد رايح مبيرجعش، فهي عبارة عن Function بتديها الـ Password ومينفعش تعمل عكس العملية دي عشان تعرف الـ Password .
وفي نفس الوقت لو حصل اي اختراق والـ Attacker وصل للـ Passwords فهو مش هيقدر يستعملها في الـ Application لانها Hashed .. ومن أمثلة الـ Modern Hashing Function الـ Bcrypt واللي بعتر بطيء بسبب الـ Resources اللي بيحتاجها عشان يـ Compute الـ Hashed Value ..
Cloud Computing Models In a Nutshell
فيه بعض الـ Cloud Computing Models الشهيرة اللي بقينا بنشوفها كتير بعد توجه كتير من الشركات والناس لاستعمال الـ Cloud وهي الـ IaaS والـ PaaS والـ SaaS .. طب ايه هي المصطلحات دي ؟
Infrastructure As a Service – IaaS
خلونا نبدأ بالـ IaaS واللي هي اختصار لـ Infrastructure as a Service :
الـ IaaS هي باختصار انك تأجر أساسيات البنية التحتية اللي انت محتاجها سواء كانت Physical أو Virtualized Resources من خلال الإنترنت، فأنت بتأجر المكونات الرئيسية زي الـ Servers و الـ Storage وأجزاء الـ Network اللي محتاجها.
مثال على ده لو انت عاوز تعمل Web Application ليه وظيفة معينة ، فانت مش محتاج تروح تشتري Server عشان تشغل عليه الـ Web Application ده ، بل أصبح متاح دلوقتي انك من خلال الـ Cloud بشوية ضغطات بسيطة انك تأجر على سبيل المثال الـ Virtual Servers اللي محتاجة تقوم الـ Web Application .. بل وكمان تقدر تتحكم في الـ Scalability بتاعته من حيث انك تزود Resources أو تنقص بناء على حجم الـ Traffic .. وكل ده بشكل Automatic من غير أي عبء أو قلق ..

Platform As a Service – PaaS
الـ PaaS واللي هي اختصار لـ Platform as a Service :

مشاركة من أحمد عطية من مجتمع اقرأ-تِك اثناء كتابته للـ Python 🤣


تقدروا دلوقتي تشتركوا في اقرأ-تِك بخصم الـ 20% وتنضموا لمجتمع مهتم بالقراءة في هندسة البرمجيات بـ 50 جنيه بس 🎉
وتستمتعوا بحرية كاملة في قراءة المقالات في مواضيع مختلفة بجودة عالية زي:
Data Structure & Algorithms , System Design , Distributed Systems , Micro-Services, Clean Code, Refactoring, Databases , Web Development, DevOps وغيرهم كتير باللغة العربية!
بالاضافة لمحتوى ورقة وقلم اللي بنشرح فيه مفاهيم برمجية بطريقة سهلة وباستعمال صور توضيحية 🚀
ولو فيه مشاكل في الدفع الأونلاين فمتاح دلوقتي الاشتراك من خلال InstaPay و VodafoneCash 💪
تقدروا تتواصلوا معانا من خلال الـ WhatsApp Business أو من خلال الرسايل على مواقع التواصل الاجتماعي أو من خلال البريد الالكتروني contact@eqraatech.com 😍

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
