
VOL29: Dropbox's Chrono - Scalable, Consistent and Metadata Caching Solution
أهلًا وسهلا بكم في العدد التاسع والعشرين من النشرة الأسبوعية لاقرأ-تِك 🎉


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد التاسع والعشرين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية, من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة, ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

Dropbox's Chrono: Scalable, Consistent and Metadata Caching Solution
CQRS Architecture Pattern
Improving Performance of Software Systems on Backend Level
Sessions vs Cookies
Database Normalization
ستجدون أيضًا في هذه النشرة:
الشراكات - Sponsorship
قناة التليجرام مجانية للجميع حتى يصلك كل مقال جديد
كيفية كتابة مقالات معنا في اقرأ-تِك: والمقالات تكون متاحة ومجانية للجميع ومحفوظة باسم الكاتب بكل تأكيد
كيفية الاشتراك في اقرأ-تِك من خلال InstaPay و VodafoneCash
Dropbox's Chrono: Scalable, Consistent and Metadata Caching Solution
عملية تخزين الـ Metadata واسترجعاها كان من فترة طويلة محور أساسي ومهم لفرق الـ Metadata في Dropbox ومؤخرًا فريق المهندسين عمل تحسينات ملحوظة في البنية التحتية.
التحسينات دي كان من ضمنها إنهم يبنوا الـ Scalable Key-Value Storage الخاص بيهم تدريجيًا ، وبالشكل ده قدروا إنهم يتجنبوا احتياجهم الأساسي لمضاعفة الـ Hardware.
ولكن مع تطورهم ومع وجود Scale كبير ، ده برضو كان قصاده تحديات مستمرة مقدروش إنهم يتجنبوها بسهولة.
Context
الـ Internal Clients اللي بيستعملوا Dropbox Metadata فضلوا لمدة طويلة بيعتمدوا على فرضية إن البيانات اللي هيتم استرجاعها لازم توفر ضمان الـ read-after-write فعلى سبيل المثال:
لما نيجي نعمل عملية Write لـ Key معين وبعدين علطول نعمل عمليات قراءة متتابعة للـ Key ده ، المفترض اني اقدر اشوف اللي عملتله Write بمعنى أدق لازم دايمًا أشوف الـ Recent Value اللي حصلت من عملية الـ Write ولا مجال لوجود Stale Values.
ولو كان فريق الـ Metadata كبر دماغه وقال إن الضمان ده مش مهم ، خصوصًا في أغلب التطبيقات الحالية اللي بتعتمد على الـ Eventual Consistency ، كان هتبقى مشكلة كبيرة من ناحية الـ Auditing وإنهم يغيروا كل الـ Client Code الخاص بالفرق التانية ، وده كان هيضطرهم لمجهود كبير جدًا ومضاعفات من ناحية الـ Client Side وكان هيقلل من سرعة فرق التطوير والـ Product Teams كذلك.
فعشان يحلوا مشكلة الـ High-Volume Read QPS واللي بتعرف برضو بالـ "Queries Per Second" المهولة اللي بتحصل عندهم وفي نفس الوقت يظلوا محافظين على توقعات الـ Client بتوعهم من ناحية الـ Read Consistency وعدم وجود Stale Reads ، فالحلول التقليدية من الـ Caching ما كنتش هتنفع.
فكان لا بد من وجود Scalable Consistent Caching Solution عشان يحل المشكلة دي.
Chrono
ومن هنا جه Chrono وهو عبارة عن Scalable و Consistent Caching System مبني فوق Key-Value Storage System بيستعملوه وهو Panda. وقادر إنه يعيش ويـ Survive مع الكميات المهولة من عمليات القراءة والـ High-Volume Read QPS.
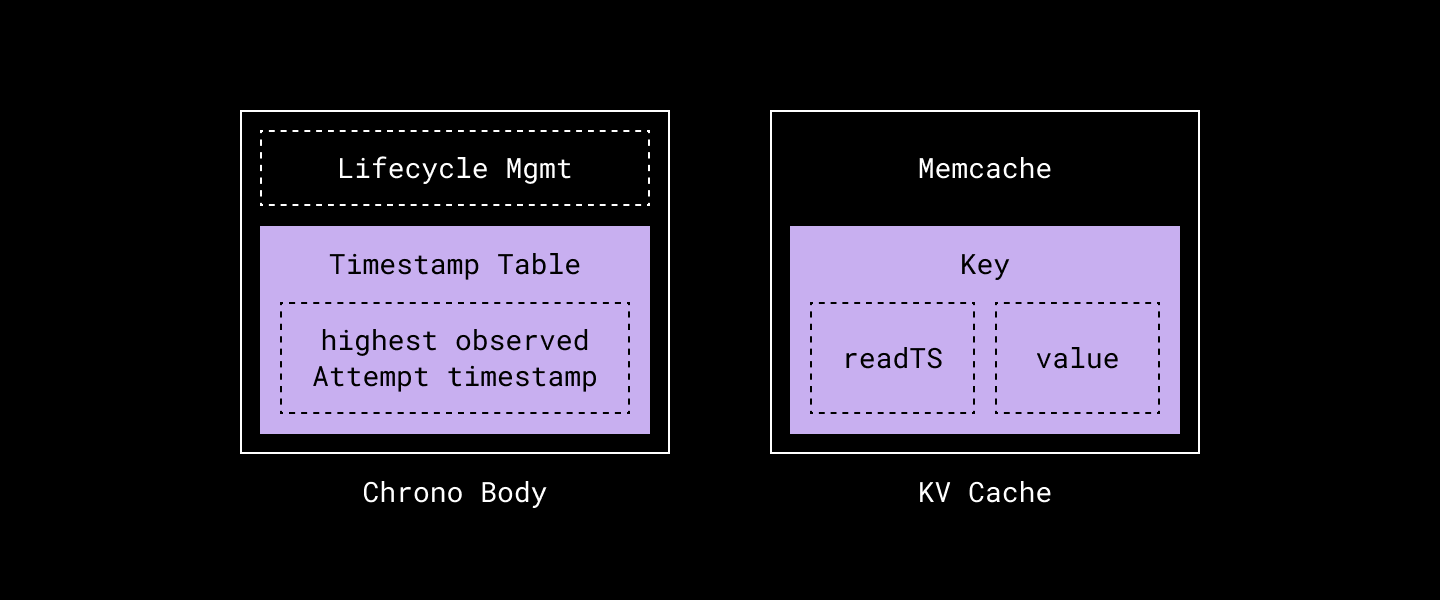
مصدر الصورة : Dropbox Engineering Blog
{kind=link}
Consistent Caching Challenges
استخدام الـ Caching بشكله البسيط والتقليدي في الـ Database Layer مش بيدينا ضمانات القراءة بعد الكتابة "Read-After-Write" اللي عاوزين نحققها. فمثلًا، لو كتبنا في قاعدة البيانات وبعدها كتبنا في الـ Caching، ممكن يحصل إن الـ Server يتعطل بين العمليتين، وده يخلي البيانات اللي في الـ Caching قديمة.
وحتى الطرق البسيطة لتحديث الـ Caching مش بتكون مضمونة. فخلونا نتخيل السيناريو ده: لو عندنا القيمة القديمة للـ Key = K في الـ Storage هي v1، وفي الـ Cache هي كمان v1:
الـ Writer لو حاول يكتب K=v2 فاحنا في البداية محتاجين نمسح القيمة القديمة من الـ Cache للـ Key = K.
الـ Reader 1 وهو بيقرأ من الـ Cache مش هيلاقي حاجة وده لإننا مسحناها، فهيروح يقرأ من الـ Storage Layer نفسها وهيلاقي إن النتيجة هي v1.
الـ Writer بعد كده بيكمل الكتابة عادي جدًا في الـ Storage ويخزن v2.
الـ Reader 2 وهو بيقرأ من الـ Cache مش هيلاقي حاجة، فهيروح يقرأ من الـ Storage Layer وهيلاقي v2 ووقتها هيخزنها في الـ Cache إن الـ K = v2.
الـ Reader 1 في الأول حصله Cache Miss وبالتالي قرأ من الـ Storage Layer إن الـ K = v1 فهو دلوقتي هيروح يكتب v1 في الـ Cache بعد ما عمل Cache Invalidation.
فهنلاقي إن النتيجة إن الـ Cache دلوقتي بيحتوي على بيانات قديمة بالنسبة للـ Storage Layer. نتيجة إن فيه Concurrent Read حصلت وبينهم حصل Concurrent Cache Miss واثناء ما كل Reader بيحاول يـ Invalidate الـ Cache بالقيمة الجديدة فيه واحد عمل Write على التاني بالقيمة القديمة.
CQRS Architecture Pattern
بناء البرمجيات زي بناء المباني بالظبط محتاج ترتب أجزاء المبني وعلاقتهم ببعض بطريقة مناسبة لوظيفة المبني والمستخدمين, فالبيت مبني وكذلك الجامعة مبني ولكن الحجم, والوظيفة والمستخدمين مختلفين ومن هنا بتيجي فكرة ال Architectural Patterns في البرمجيات.
والشطارة بتكون في ازاي استخدم النمط الأكثر إفادة لوظيفة وحجم ونوع الاستخدام لمشروعي اللي شغال عليه.
Command Query Responsibility Segregation (CQRS)
في معظم مشاريعنا بنستخدم CRUD Pattern وبنعتمد علي الوظائف الأساسية فيه زي Create, Read, Update, Delete وبالفعل هو نمط مناسب للمشاريع البسيطة والصغيرة والمتوسطة في الحجم لأنه سهل.
ولكن في حالات بنحتاج فيها Data Manipulation اكثر من الـ CRUD يقدر يقدمه , زي اننا نشتغل في Business العلاقات فيه بين ال objects معقدة أكتر أو تطبيق يكون فيه استهلاك البيانات فيه عالي وكذلك كتابتها ودا بيوقعنا في مشكلة لأن متطلبات الـ Scaling في حالة الـ Heavy Reads تختلف عن متطلباته في حالة الـ Heavy Writes
ال CQRS اختصار لـ Command Query Responsibility Segregation أو Separation وهو نمط هدفه الفصل بين الـ Commands و الـ Queries في الكود وبنعّرف فيه:
الأوامر (Commands): : هي عملية كتابة أو تغيير البيانات وهي العمليات اللي فيها بتتغير حالة النظام. والأوامر جي بتقوم بـ "فعل" شيء وتؤثر على حالة النظام.
الاستعلامات (Queries): عملية قراءة البيانات وهي العمليات اللي بتسترجع بيانات و لكن لا تغير حالة النظام. بمعنى أنها "تسأل" عن شيء معين ولا تعدل أي شيء.

الـ CQRS يستخدم اثنين من الـ Models المختلفة عشان يحقق الأوامر (Commands) بالـ Model المناسب ليها و كذلك Model خاص بالـ للاستعلامات (Queries). وبما إن دا Architectural Pattern فبيسيب للمبرمج حرية اختيار وتنويع الـ Models اللي شايفها بتحقيق الهدفين دول وايه الأنسب لمشروعه وده بيدينا مرونة في التنفيذ.
كمان نقدر في تنفيذه نستخدم 2 من قواعد البيانات -الطريقة الأكثر شيوعًا- واحدة مخصصة للاستعلامات وواحدة للأوامر ويتعمل بينهم Synching.
الشراكات - Sponsorship
بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship وتقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 🚀
لا تدع شيء يفوتك!

بفضل الله قمنا بإطلاق قناة اقرأ-تِك على التليجرام مجانًا للجميع 🚀
آملين بده اننا نفتح باب تاني لتحقيق رؤيتنا نحو إثراء المحتوى التقني باللغة العربية ، ومساعدة لكل متابعينا في انهم يوصلوا لجميع أخبار اقرأ-تِك من حيث المقالات ومحتوى ورقة وقلم والنشرة الأسبوعية وكل جديد بطريقة سريعة وسهلة
مستنينكوا تنورونا , وده رابط القناة 👇
Improving Performance of Software Systems on Backend Level
سنتناول في هذا المقال بعض النصائح لتحسين الأداء في الـ Backend ، ولقد تناولنا في مقال سابق كيفية تحسين الأداء على مستوى الـ Frontend ويمكنكم مشاهدة المقال من هنا

Code & Programming Logic
وأقصد به كتابة الكود وفق المنطق السليم وتعقيد زمني سريع في بناء واختيار الخوارزميات وهياكل البيانات, فأحد أهم وظائف الـ Backend في إطار الأنظمة والتطبيقات, هو تنفيذ العمليات المنطقية في الإدارة والتنظيم للعمليات والمعلومات في النظام ، وعلى ذلك لابد من ضمان سرعة تنفيذ هذه المهام والعمليات بأفضل طريقة وأسرع مدة
Multithreaded Programming & Asynchronous Programming
من المهم جداً بالنسبة لمبرمج ال backend عن يدرك الفرق بين مفهومي ال Multithreading و ال asynchronous programming
حتى يراعي الأنسب في بناء الأنظمة والتطبيقات فتطبيقهما بشكل صحيح يحقق:
تنفيذ العمليات ومعالجة الطلبات بشكل سريع
استيعاب ضغط الطلبات وكثرتها بشكل متزامن Concurrency
فإذا كان النظام يعتمد في الأساس على عمليات معالجة تستند إلى CPU bound tasks كالعمليات الحسابية المعقدة مثلاً، فمن الأفضل أن يستخدم في هذه الحالة لغات البرمجة وأطر العمل التي تدعم الـ Multi threading.
وفي حال كان النظام يعتمد على عمليات I/o bound مثل التعامل مع الملفات او إرسال طلبات http من الأفضل الاعتماد على لغات البرمجة وأطر العمل التي تدعم ال asynchronous programming.
ولا يوجد مانع من الاستخدام الاثنين في لغة وإطار يدعم الاثنين, ولكن المشكلة ستظهر في حال فقد أحدهما مع الحاجة إليه فإن فارق الأداء سيظهر حينها بشكل ملحوظ عندما يبدأ ال requests load القوي على النظام>
وعلى الرغم من لغات البرمجة واطر العمل تدير الـ threads في وال asynchronous operation بشكل يساعد المبرمج إلى حد كبير, فإن ذلك لا يخلي بالكامل مسؤولية المبرمج في الفهم والتعامل معهما بالشكل الصحيح في الكود.
Sessions vs Cookies
في الـ Web Development فيه مشكلة بتقابلنا الا وهي ان الـ HTTP بطبعه بيكون Stateless يعني مش بيحتفظ بأي بيانات , وعشان نعالج المشكلة دي ونخلي فيه State موجودة نقدر من خلالها ندير البيانات ونخزنها , ظهر الـ Cookies والـ Sessions
فهما أدوات أساسية لإدارة البيانات وتخزينها أثناء تفاعل المستخدمين مع المواقع, بالرغم من تشابههم في بعض الجوانب، إلا أن كل واحد منهم ليه استخدامات وخصائص مميزة. هنشرح بالتفصيل الفرق بينهم وامتى بنستخدم كل واحد فيهم
الـ Cookies
الـ Cookie هي ملف نصي صغير بيتم تخزينه في جهاز المستخدم (زي الكمبيوتر أو الموبايل) بواسطة المتصفح. الهدف الرئيسي من الـ Cookie هو تخزين معلومات بسيطة بتساعد الموقع في تذكر المستخدم والتفضيلات بتاعته.
استخدامات الـ Cookies
الـ Cookies ليها استعمالات كتير من ضمنهم:
تسجيل الدخول: المواقع بتستخدم الـ Cookies علشان تفتكر المستخدمين المسجلين وتوفر عليهم عناء تسجيل الدخول كل مرة.
تتبع النشاط: المواقع بتستخدم الـ Cookies لتتبع سلوك المستخدمين وتحليل نشاطهم لتحسين الخدمات والإعلانات.
تخصيص المحتوى: بتساعد الـ Cookies في تخصيص تجربة المستخدم عن طريق تذكر تفضيلاته، زي اللغة المفضلة أو ثيم الموقع.
مدة تخزين الـ Cookie
فيه نوعين من الـ Cookies الا وهم الـ Session Cookie والـ Persistent Cookie وكل واحد فيهم بتختلف مدة تخزينه عن التاني:
Session Cookies: بتنتهي بمجرد ما المستخدم يقفل المتصفح.
Persistent Cookies: بتفضل موجودة لفترة محددة بيحددها المطور، وبتنتهي أوتوماتيك بعد المدة دي.

الـ Cookies والـ Security
الـ Cookies ممكن تتعرض لهجمات زي XSS (Cross-Site Scripting) لو المطور مش واخد احتياطاته الكافية, وعشان كده البيانات الحساسة ما ينفعش نخزنها ابدًا في الـ Cookies.
احيانا كتير استخدام خواص زي HttpOnly وSecure Attributes بيساعد في حماية الـ Cookies من الهجمات.
Database Normalization
أما بنروح المكتبة بنلاقي الكتب والروايات والمراجع مقسمة بشكل كويس يسهل للناس انها تروح تجيب اللي هي عاوزاه من غير ما تبذل مجهود كبير , نفس الكلام في الدولاب اما بتكون الهدوم مترتبة ده هيسهل عليك انك تلاقي اللبس اللي انت محتاجه بسهولة.
وهي دي ببساطة فكرة الـ Database Normalization هي عملية الـ Categorization أو الفصل اللي بنعمله بحيث نخلي كل جزء مترتب في مكان لوحده.
تعالوا نتخيل ان عندنا بيانات مجموعة من الطلاب , بس بيانات الطلاب دي كلها موجودة في Table واحد , الـ Table ده يشتمل على ايه ؟ يشتمل على كل حاجة خاصة بالطالب (بيانات الطالب - الكورسات اللي بيشوفها - درجاته - المدرسين اللي بيشرحوله) الخ..
اللي عندنا ده دلوقتي اسمه Database De-Normalization طب ايه الـ Database Normalization ؟
الـ Normalization هو اني ابدأ اعمل Categorization واعمل فصل لبيانات الطلاب دي فاخلي بيانات الطالب في Table وليكن Students اخلي الكورسات في Table تاني اسمه Courses وهكذا..
فبدل ما كان عندي Table واحد كبير فيه البيانات كلها , اصبح دلوقتي عندي اكتر من Table وكل واحد شايل الجزء الخاص بيه او الـ Category بتاعته بمعنى اصح.
طب ايه الفرق بين الـ Normalization والـ De-Normalization , وايه مميزات وعيوب كل واحد منهم , ده اللي هنعرفه انهاردة 🎉
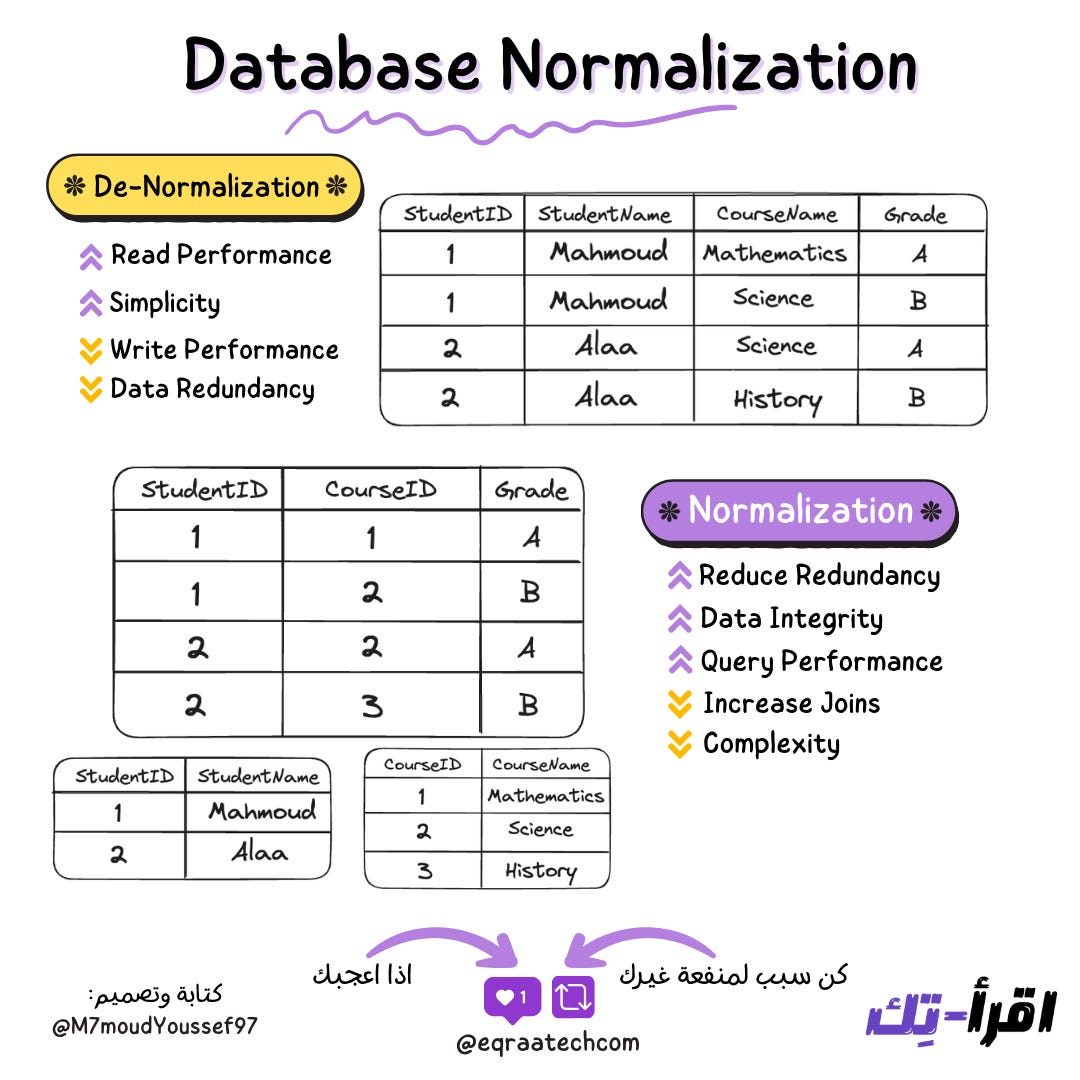
مميزات الـ Normalization
Reduce Redundancy
أول ميزة مهمة من الـ Normalization هي أنه بيقلل التكرار اللي ممكن يحصل, فزي ما شوفنا لو انا عندي بيانات الطلاب في Table واحد , لو كان عندي Student Enrolled في 5 كورسات هيكون عندي 5 Entries
الفكرة مش في كده بس الفكرة ماذا لو بيانات الطالب دي كبيرة يعني بتشتمل على (عنوان - اسم - رقم تليفون - ايميل) وتفاصيل تانية كتير ؟ هنلاقي ان كل البيانات دي بتتكرر
ولكن لو لجأنا للـ Normalization فاحنا هنقلل الـ Storage وهتبقى Efficient لاننا ممكن نبدل كل ده بالـ StudentID ويكون بيانات الطالب في Table منفصل والـ Courses كذلك.
Improve Data Integrity
اما بنفصل كل جزء خاص بيه لوحده من خلال الـ Normaliztion , عمليات الـ Update والـ Modifications عامة هتكون أقل عرضة للمشاكل وده لانك بتغير في مكان واحد بس , فانت لو بتغير عنوان الطالب مش محتاج تروح تغيره في 5 اماكن في نفس الـ Table وبالتالي بتكون أقل عرضة للمشاكل وتحسن من الـ Data Integrity
Enhance Query Performance
ده هيحسن بنسبة كبيرة من الـ Query Performance خصوصا في عمليات الـ Write وكذلك الـ Fetching بنسبة بسيطة خصوصا اني دلوقتي باه عندي Tables صغيرة + الـ Indexing هيكون على كل Table منهم فهيساعد في تحسين الـ Overall Query Performance ولكن فيه عيب قاتل هنتكلم عنه في العيوب ليه علاقة بالـ Joins فهي مش معانا دلوقتي.


قولنا ميت مرة نهتم بالـ Clean Code والـ Documentation 😂💔

تقدروا دلوقتي تشتركوا في اقرأ-تِك بخصم الـ 20% وتنضموا لمجتمع مهتم بالقراءة في هندسة البرمجيات بـ 50 جنيه بس 🎉
وتستمتعوا بحرية كاملة في قراءة المقالات في مواضيع مختلفة بجودة عالية زي:
Data Structure & Algorithms , System Design , Distributed Systems , Micro-Services, Clean Code, Refactoring, Databases , Web Development, DevOps وغيرهم كتير باللغة العربية!
بالاضافة لمحتوى ورقة وقلم اللي بنشرح فيه مفاهيم برمجية بطريقة سهلة وباستعمال صور توضيحية 🚀
ولو فيه مشاكل في الدفع الأونلاين فمتاح دلوقتي الاشتراك من خلال InstaPay و VodafoneCash 💪
تقدروا تتواصلوا معانا من خلال الـ WhatsApp Business أو من خلال الرسايل على مواقع التواصل الاجتماعي أو من خلال البريد الالكتروني contact@eqraatech.com 😍

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
