
VOL28: Unlocking Notion's Power - The Data Model Explained
أهلًا وسهلا بكم في العدد الثامن والعشرين من النشرة الأسبوعية لاقرأ-تِك 🎉


لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸
أهلًا وسهلا بكم في العدد الثامن والعشرين من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هدفها انها تثري المحتوى التقني العربي سعيا للتطوير من جودة المحتوى باللغة العربية, من خلال تقديم أحدث المستجدات والتطورات في عالم البرمجيات، بالإضافة إلى أفضل الممارسات والنصائح القيمة, ونشر أحدث المقالات وترشيحات الكتب ومحتوى ورقة وقلم اللي بينزلوا بشكل مستمر في موقع اقرأ-تِك.
في الإصدار ده الفهرس هيكون كالآتي:

Unlocking Notion's Power - The Data Model Explained
Generative AI In a Nutshell
Process Scheduling
URL Explanation In a Nutshell
Protocol Buffer (ProtoBuf)
ستجدون أيضًا في هذه النشرة:
الشراكات - Sponsorship
قناة التليجرام مجانية للجميع حتى يصلك كل مقال جديد
كيفية كتابة مقالات معنا في اقرأ-تِك: والمقالات تكون متاحة ومجانية للجميع ومحفوظة باسم الكاتب بكل تأكيد
كيفية الاشتراك في اقرأ-تِك من خلال InstaPay و VodafoneCash
Unlocking Notion's Power - The Data Model Explained
فريق المهندسين لم جم يبنوا Notion، كانوا حريصين على بناءه على إطار عمل يسمح للمعلومات إنها تقف لوحدها، حرة من أي قيود أو حاويات، وبدل ما تكون محبوسة في أي حاجة، بنخلي القوة في إيد المستخدم انه يقرر ده ، والإطار ده مبني على مفهوم غاية في الابداع ألا وهو الكتل (blocks).
كل حاجة بنشوفها في Notion هي block. النصوص، الصور، القوائم، صفوف قاعدة البيانات، وحتى الصفحات نفسها – كلها عبارة عن blocks، فهي وحدات ديناميكية من المعلومات اللي ممكن تتحول لأنواع تانية من blocks أو تتحرك بحرية داخل Notion.
الكتل دي هي زي قطع LEGO اللي بنستخدمها في بناء ونمذجة المعلومات. ولما بتتجمع الكتل مع بعضها، بتخلق حاجة أكبر بكتير من مجرد تجميع أجزائها.
والمرونة اللي بنشوفها من خلال Notion والـ Blocks هي جوهر مهمة Notion. فعلى الرغم من أن الكتل بتطلب من فريق Notion الهندسي إنه يكون بيطبق دقة شديدة خلال تنظيم المعلومات، الا إنهم كانوا عاوزين نموذج بيانات شبيه بالرسم البياني (graph-like) بحيث يقدر يوفر للمستخدمين القدرة على تخصيص حركة وتنظيم ومشاركة المعلومات بتاعتهم بحرية كاملة.
نموذج الكتل (Blocks) هو اللي بيخلي Notion فريد، وده الأساس لطريقة تفكير Notion في انهم يغيروا من طريقة التعامل مع البيانات.
Fundamentals of Blocks in Notion
زي قطع الـ LEGO في مجموعة LEGO، كتل Notion هي القطع الفردية اللي بتمثل كل وحدات المعلومات جوه محرر Notion. وخصائص الكتلة هي اللي بتحدد إزاي المعلومات دي هتتنسق وتتنظم بالشكل اللي عاوزينه.

مصدر الصورة : Notion Engineering Blog
{kind=link}
كل كتلة عندها الخصائص دي:
الـ ID: كل كتلة ليها معرف فريد. ونقدر نشوف الـ ID الخاص بكتلة الصفحة (Page Block) في نهاية عنوان الـ URL في المتصفح. وبيتم استعمال الـ UUIDs (UUID v4) كمولد عشوائي للـ IDs في Notion.
الـ Properties: وهي عبارة عن هيكل بيانات بيحتوي على بعض خصائص المخصصة لكتلة معينة. فالخاصية الأكثر شيوعًا هي الـ title، ودي اللي بتخزن محتوى النص لأنواع الكتل زي الفقرات والقوائم وطبعًا عنوان الصفحة. والأنواع الأكثر تعقيدًا من الكتل بتحتاج خصائص إضافية أو مختلفة.
الـ Type: كل كتلة ليها نوع، وده اللي بيحدد إزاي الكتلة هتظهر ويتعملها Render بشكل مختلف، وإزاي هنفسر خصائص الكتلة. Notion بيدعم أنواع كتير من الكتل، واللي ممكن تشوف أغلبها في قائمة "new block" لما تدوس على زر + أو في قائمة /.

مصدر الصورة : Notion Engineering Blog
{kind=link}
إلى جانب الخصائص اللي بتوصف الكتلة نفسها، كل كتلة بيكون عندها مجموعة من الخصائص اللي بتحدد علاقتها مع باقي الكتل وهنا ممكن نشوف الموضوع أشبه بـ Graph:
الـ Content: ودي عبارة عن Array من معرفات الكتل (Block IDs) اللي بتمثل المحتوى جوه الكتلة دي، زي العناصر المتداخلة في قائمة نقطية أو النصوص جوه toggle فأشبه بالـ Children للـ Parent.
الـ Parent: وده عبارة عن معرف الكتلة اللي هي الأصل للكتلة الحالية. أو بمعنى أدق الـ Parent of Current Block ، وكتلة الأصل بتستخدم فقط في صلاحيات الوصول (permissions).
How Blocks Fit Altogether
زي كتل الـ LEGO، كتل Notion ممكن تتجمع مع كتل تانية عشان تعمل حاجة أقوى بكتير – زي الـ Roadmap اللي بتكون مخصصة تمامًا للـ Progress بتاع فريقك، وبترصد التقدم وبتحتفظ بكل معلومات المشروع في مكان واحد. فـ Notion هم بينظموا كل جوانب الكتل عشان يتأكدوا إنها بتعمل الحاجات الصح وبتعيش في الأماكن الصح، وده بيسهل للمستخدمين استعمالها وربطها وتخصيصها زي ماهم عاوزين عشان يحلوا مشاكلهم ويديروا مشاريعهم بكفاءة.
Block Types and Properties
نوع الكتلة في Notion هو اللي بيحدد إزاي الكتلة هتتعرض ويتعملها Render في واجهة مستخدم Notion، وطبقًا لنوعها، بيتم ترجمة خصائص ومحتويات الكتلة بشكل مختلف.
والموضوع ده ممكن يكون واضح شوية مع الخاصية دي لو في حد استخدم وظيفة "Turn into" في Notion، اللي بتسمحلنا نحوّل نوع الكتلة لنوع تاني خالص.
تغيير نوع الكتلة مش بيغير الخصائص أو المحتوى – بيغير بس الخاصية اللي بتحدد النوع. المعلومات بتتعرض بشكل مختلف أو ممكن حتى يتم تجاهلها لو الخاصية دي مش مستخدمة مع نوع الكتلة ده.
خلونا ناخد مثال يوضح الموضوع بشكل أبسط:
ممكن نشوف هنا إن كتلة الـ To-do list اتحولت لأنواع تانية من الكتل. وإحنا كمان كنا معلمين على عنصر في To-do list. فهنلاقي أن الخاصية "checked" في كتلة To-do list بيتم تجاهلها لما الكتلة تتحول لنوع Heading أو Callout – لكن لما نرجع نحول الكتلة لـ To-do list مرة تانية، هتفضل معلمة و Checked زي مهي.
مصدر الفيديو : Notion Engineering Blog
Generative AI In a Nutshell
من سنة بالضبط وفي وقت ما معلوماتنا كمبرمجين عن الـ AI كانت واقفة انه بيعرف يفرق بين صورة قطة وصورة كلب و شوية استخدامات بسيطة , خرج للنور ChatGPT وتبعه الكثير من ال AI Apps اللي كانت قادرة تنتج داتا جديدة أول مرة نشوفها وترد علينا زي ما الناس بترد علينا.
Generative AI
ال Generative AI هو فئة من فئات الـ AI اللي عندها القدرة على إنتاج محتوى جديد, سواء ردود على اسئلة أو صور أو مقاطع صوت أو فيديو ، وفي الواقع النوع دا من ال AI مش حاجة جديدة بل موجود من 1960 و احنا اتعاملنا معاه كتير قبل ChatGPt في هيئة ال Chat Bots ودي AI Apps قادرة تعمل محادثات زي البشر.
الـ AI Apps دي كانت محدودة المعلومات ومتقدرش تفهم كل الاسئلة اللي بتوجه لها ولا تقدر تفهم سياق المحادثة الكلي لأنها معتمدة علي Rule-Based Models ودي Models بيبرمج فيها الانسان قواعد وشروط ثابتة فتبدو كأنها بتنتج ردود ولكن الردود دي مبرمجة مسبقًا.
بينما ال Apps الجديدة اللي بنشوفها معتمدة على تقنيات مختلفة ومرنة من ال Deep Learning Models واللي محتاجة برمجة أقل ولكن Data Sets اكبر بكتير عشان تتدرب عليها وكل لما البيانات اللي كانت بتتدرب عليها أكتر ومتنوعة أكثر كانت ال Models دي اقوي وبتدينا نتائج أحسن من غير برمجة ثابتة للردود دي.
أشهر الـ Models
أشهر ال Models اللي بنستخدمها حاليًا في ال Generative AI:
Large Language Models (LLM) ودي اللي بنستخدمها في ChatGPT و محركات الترجمة و التلخيص
Generative Adversarial Networks (GANs) و دي اللي بنستخدمها في إنتاج الصور و الفيديوهات
طيب ما برضو ال Deep Learning Models مش حاجة جديدة, امال ايه اللي عمل الطفرة دي؟

ايه الاختلاف اللي أدى لظهور الـ Generative AI
دا يعود لـ3 أسباب رئيسية
الشراكات - Sponsorship
بفضل الله أصبح متاح حاليا دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship وتقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 🚀
لا تدع شيء يفوتك!

بفضل الله قمنا بإطلاق قناة اقرأ-تِك على التليجرام مجانًا للجميع 🚀
آملين بده اننا نفتح باب تاني لتحقيق رؤيتنا نحو إثراء المحتوى التقني باللغة العربية ، ومساعدة لكل متابعينا في انهم يوصلوا لجميع أخبار اقرأ-تِك من حيث المقالات ومحتوى ورقة وقلم والنشرة الأسبوعية وكل جديد بطريقة سريعة وسهلة
مستنينكوا تنورونا , وده رابط القناة 👇
Process Scheduling
الـ Scheduler في أنظمة التشغيل هو عبارة عن العنصر اللي بيحدد إزاي وإمتى المعالجات (CPUs) تستغل وقتها في تنفيذ البرامج المختلفة. يعني لو عندنا أكتر من برنامج شغال في نفس الوقت، الـ Scheduler هو اللي بيتحكم في توزيع وقت الـ CPU على البرامج دي.
خلينا نتخيل إننا قاعدين بنذاكر وفي نفس الوقت بنحاول نرد على رسايل مابعوتالنا في السوشيال ميديا وعاوزين نشغل حاجة نسمعها. عقلنا هنا بيقوم بدور الـ Scheduler فهو اللي بيحدد إزاي هيقسم وقتنا بين التلات حاجات دول. ممكن نذاكر شوية وبعدين نرد على الرسايل وبعدين نرجع تذاكر تاني ونشغل معاها حاجة. فنفس الموضوع بالظبط بالنسبة للـ CPU والبرامج اللي شغالة.
Process
قبل ما نتكلم باه عن الـ Process Scheduling ونعرف ازاي الـ OS بيـ Schedule الـ Process ويخليها تستغل الـ CPU وازاي يبقى مخصص لكل Process ؟ محتاجين نعرف ايه هي الـ Process , وكنا اتكلمنا عنها في ورقة قبل كده نقدر نشوفها من هنا
وكنا اتكلمنا قبل كده برضو عن الـ Process Management نقدر نشوفها من هنا
Process Scheduling

فيه عندنا 3 أنواع من الـ Process Schedulers اللي أنظمة التشغيل بتستخدمهم:
الـ Long-Term Scheduler (Job Scheduler): وده المسؤول عن إنه يقرر انهي برنامج يدخل الـ Ready Queue، اللي هو Queue البرامج بتستنى فيه لحد ما الـ CPU يبقى فاضي ويبدأ يشتغل عليها. ده زي ما بنكون كده بنقرر إيه المواد اللي هنذاكرها في يومنا قبل ما نبدأ فعليا في مذاكرتها.
الـ Short-Term Scheduler (CPU Scheduler): ده بيكون المسؤول عن إنه يقرر انهي البرامج الموجودة في الـ Ready Queue هياخد الـ CPU ويبدأ يشتغل عليه فعليًا. او بمعنى اصح يعني مين اللي عليه الدور دلوقتي ياخد وقت من دماغك.
الـ Medium-Term Scheduler: وده بيشتغل في بعض الأنظمة اللي بتستخدم تقنية الـ Swapping. فبيقرر إمتى يوقف برنامج من الشغل ويطلعه برا الذاكرة (RAM) عشان يدي امكانية لباقي البرامج انها تشتغل على الـ CPU. وبعدين لما يبقى فيه مكان فاضي يرجعه تاني.
URL Explanation In a Nutshell
مش محتاج تبقي مبرمج عشان تشوف url مرة أو اثنين على الأقل في يومك بس لو مبرمج هتشوفه كتير أوي، والنهاردة هنتكلم عن أجزاءه المختلفة اللي مهم نعرفها عشان أكيد هتتعامل مع Endpoint أو Api عن طريق الـ URL هنا ولا هنا
ايه هو الـ URL ؟
الـ URL بنغلط كتير و بنقول عليه عنوان الموقع لكن في الحقيقة هو الطريقة اللي المتصفح بتاعك بيطلب بها الوصول لموقع ما، واللي أكيد هتضمن اني اجيب عنوانه ولكن ممكن يكون في أجزاء أخرى:

أجزاء الـ URL
الجزء الأول:
بيمثل الـScheme أو البروتوكول اللي السيرفر اللي شايل الموقع هيكلم بيه المتصفح بتاعك والأشهر هما HTTP و HTTPS ولكن في أنواع تانية كثير.
الجزء الثاني:
وهو عنوان الموقع نفسه ودا اسم النطاق الي الموقع ساكن فيه، و بما ان الكمبيوتر مش بيفهم انجليزي فبنحتاج DNS Server عشان يترجم الاسم دا لـIP Address عبارة عن أرقام يفهمها الكمبيوتر.
الجزء الثالث:
وهو الـ Path او عنوان تفصيلي للمحتوى اللي انت عاوزه داخل الموقع، صفحة معينة أو ملف معين داخل صفحة رئيسية أو فرعية.
دول الثلاث أجزاء المهمين اللي أساسي تواجدهم داخل الـ URL وبتشبيه بسيط: الـ URL هو عنوان البيت + عنوان الغرفة أو الشيء اللي عاوز توصله داخل البيت.
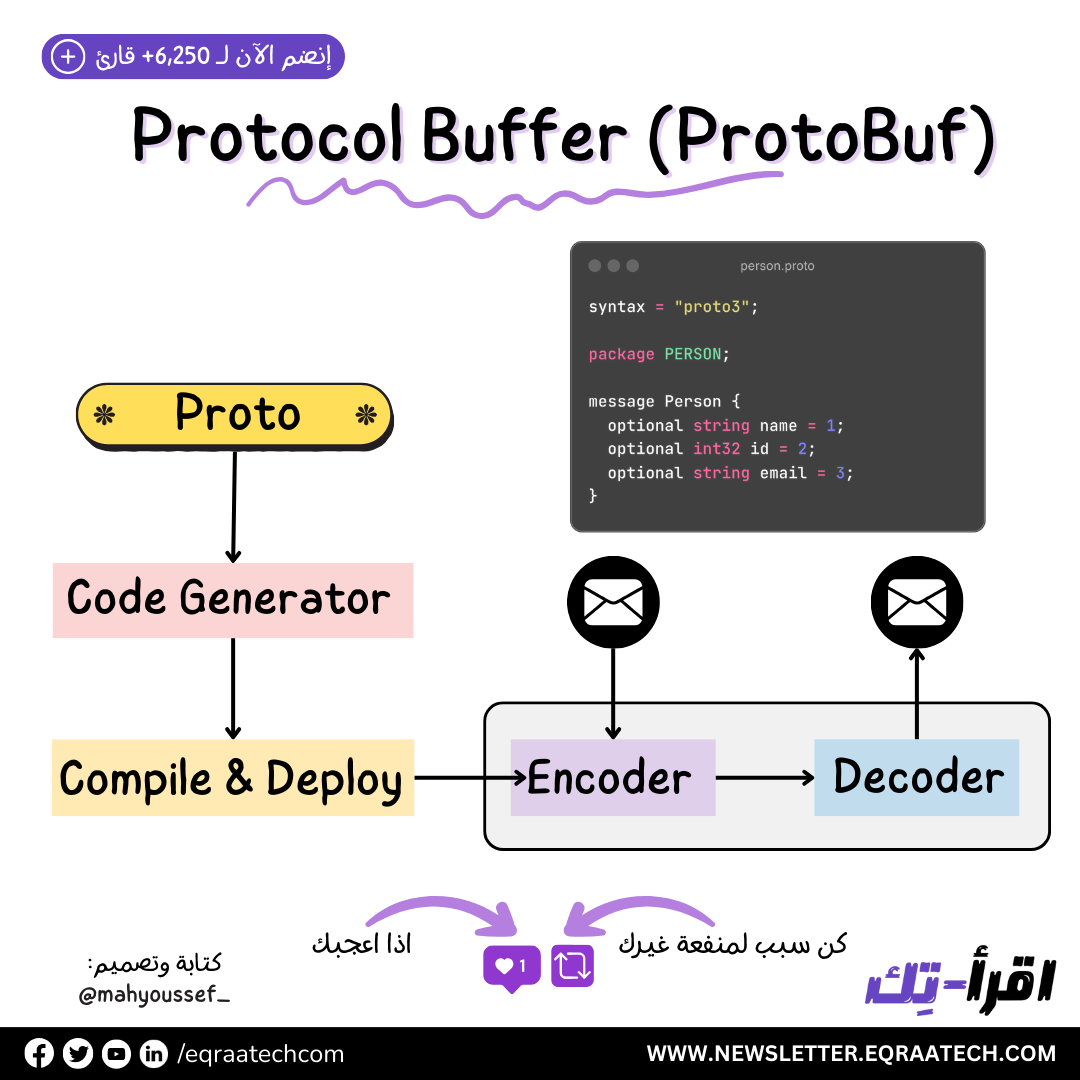
Protocol Buffer (ProtoBuf)
اختيار الـ Format المناسب للـ Data Serialization أصبح موضوع حيوي حاليًا خصوصًا في التعامل مع الأنظمة اللي بتتميز بكونها Large-Scale واللي الأداء فيها حيوي ومهم جدًا. ومن أشهر الـ Formats اللي فضلت موجودة على مر السنين هو الـ JSON وهو اختصار لـ JavaScript Object Notation.
ولكن بسبب احتياج الـ Large-Scale Systems للأداء العالي والـ Bandwidth القليلية ظهر Format تاني ألا وهو الـ ProtoBuf.
طب ايه هو الـ ProtoBuf وايه سبب ظهوره ؟ وايه اللي بيميزه عن الـ JSON وليه بنختاره في الـ Large-Scale Systems ، ده اللي هنعرفه انهاردة فورقة وقلم وتعالوا نتكلم عن الـ ProtoBuf vs JSON 🚀
Protocol Buffer (ProtoBuf)
الـ Protocol Buffer أو الـ ProtoBuf هو طريقة طورتها Google عشان تعمل بيها Serialization للـ Structured Data. بالإضافة لإنه مش معتمد على لغة برمجة بعينها أو Platform بعينه.
وممكن يتم الاعتماد عليه في الـ Communication بين الـ Services وبعضها أو في أي موقف احتجنا فيه إننا نخزن بيانات أو نتبادل بيانات تكون Structured.
بالإضافة لإنه كمان نظام مفتوح المصدر (open-source).
JSON vs. ProtoBuf
الـ JSON معروف عند كتير من المطورين، وبيستخدموه في كتير من التطبيقات عشان ينقلوا البيانات ما بين الـ Client والـ Server. لكن فيه فروق مهمة بينه وبين الـ ProtoBuf واللي في الأساس أدت لظهوره:
الحجم: الـ ProtoBuf بيـ Serialize البيانات بطريقة مدمجة أكتر من الـ JSON، وده معناه إن البيانات اللي معملوها Serialization بالـ ProtoBuf بتاخد مساحة أقل، وده بيفرق جداً لو بتتعامل مع بيانات كبيرة أو بتبعتها على الشبكة فبالتالي بيكون عندك Bandwidth أقل على عكس الـ JSON.
الأداء: الـ ProtoBuf أسرع في قراءة وكتابة البيانات مقارنة بـ JSON. وده لإنه بيخزن البيانات على هيئة Binary مش نصوص Texts زي JSON، وده بيخلي العمليات أسرع بكتير وعشان كده ناس كتير بتفضل الـ JSON عشان الـ Human Readable لإنه Text ممكن يبقى أسهل كتير في الـ Debugging والشغل معاه.
قابلية التوسع أو ما يعرف بالـ Extensibility: الـ ProtoBuf بيتيح ليك تضيف أو تعدل في البيانات اللي بتعملها Serialize بدون ما تتسبب في مشاكل للنسخ القديمة. يعني بيحقق الـ Backward Compatibility على عكس JSON مفيهوش نفس المرونة دي، وأي تغيير ممكن يعمل مشاكل في التعامل مع البيانات القديمة. وبيظهر هنا قوة الـ ProtoBuf من خلال الـ Optional والـ Required اللي من خلالهم تقدر تتحكم في الـ Fields.
سهولة القراءة Human-Readability: الـ JSON بيتميز إنه مقروء للإنسان بشكل مباشر، يعني تقدر تشوف البيانات وتفهمها بسهولة. على العكس، الـ ProtoBuf بيخزن البيانات في هيئة Binary مش مفهومة للبشر، وده ممكن يكون عيب لو بتحتاج تقرأ البيانات بشكل مباشر. ولكن بالطبع فيه Tools بتمكنك انك تـ Parse الـ Binary دي وتقرأهم ولكن الموضوع مش مباشر زي الـ JSON.

مشاركة من أحمد عطية في مجتمع اقرأ-تِك 😂

وده بيكون حال معظمنا خصوصًا في الـ Sprint Planning 🤣

تقدروا دلوقتي تشتركوا في اقرأ-تِك بخصم الـ 20% وتنضموا لمجتمع مهتم بالقراءة في هندسة البرمجيات بـ 50 جنيه بس 🎉
وتستمتعوا بحرية كاملة في قراءة المقالات في مواضيع مختلفة بجودة عالية زي:
Data Structure & Algorithms , System Design , Distributed Systems , Micro-Services, Clean Code, Refactoring, Databases , Web Development, DevOps وغيرهم كتير باللغة العربية!
بالاضافة لمحتوى ورقة وقلم اللي بنشرح فيه مفاهيم برمجية بطريقة سهلة وباستعمال صور توضيحية 🚀
ولو فيه مشاكل في الدفع الأونلاين فمتاح دلوقتي الاشتراك من خلال InstaPay و VodafoneCash 💪
تقدروا تتواصلوا معانا من خلال الـ WhatsApp Business أو من خلال الرسايل على مواقع التواصل الاجتماعي أو من خلال البريد الالكتروني contact@eqraatech.com 😍

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
