
Engineering Radar #1: AI Major Updates of Frontier Models
كل اللي محتاج تعرفه عن عودة Fable 5 و إطلاق GPT-5.6 Sol وكمان النموذج مفتوح المصدر الأقوى حاليًا GLM-5.2

لا تنسوا أهلنا من صالح الدعاء,اللهم إنّا استودعناك اياهم، اللهم كُن عوناً لهم، اللهم انصرهم واحفظهم. 🇵🇸 🇸🇩
أهلًا وسهلًا بكم في أول عدد مميز من سلسلة Engineering Radar من النشرة الأسبوعية لاقرأ-تِك 🚀
سواء كنت مهندس برمجيات مبتدئ أو محترف، فنشرتنا هتساعدك على مواكبة أحدث تطورات عالم البرمجة بمواضيع جديدة كل أسبوع، هتلاقى كمان محتوى عملي بيشمل أفضل الممارسات، ونصائح مفيدة، وترشيحات لمقالات مختارة من اقرأ-تِك.
أخبار الـ AI كترت علينا أخر 10 أيام فقولنا نميز العدد ده بأهم الأخبار ونشوف ازاي نستفيد منها كمبرمجين, فيلا بينا!

🌟 مواضيع النشرة لهذا الأسبوع 🌟
OpenAI Previews GPT-5.6 Sol 🌞
Claude Fable 5 has Returned 🚀
GLM-5.2 :The Open Source Finally in the Frontier 🔥
OpenAI Previews GPT-5.6 Sol
أعلنت OpenAI عن إطلاق نسخة تجريبية محدودة من نموذجها الجديد GPT-5.6 Sol، تحت إشراف الحكومة الأمريكية.
الشركة كمان نزلت نموذجين أقل سعرًا:
Terra: بسعر يقارب نصف سعر GPT-5.5 مع أداء متقارب.
Luna: كخيار اقتصادي منخفض التكلفة.
وبحسب المتطلبات الحكومية، الإطلاق هيبدأ مع 20 شريك موثوق فقط الحكومة هي اللي قامت باختيارهم، لحد ما يتم حسم شروط الإتاحة العامة، واللي متوقع تحصل من نصف لأخر يوليو.

من ناحية الأداء، GPT-5.6 Sol حقق 88.8% على اختبار TerminalBench 2.1 الخاص بال Coding Agents ، متفوقًا بشكل طفيف على Claude Mythos 5 اللي سجل 88%. أما وضع “Ultra” متعدد الوكلاء فوصل إلى 91.9%
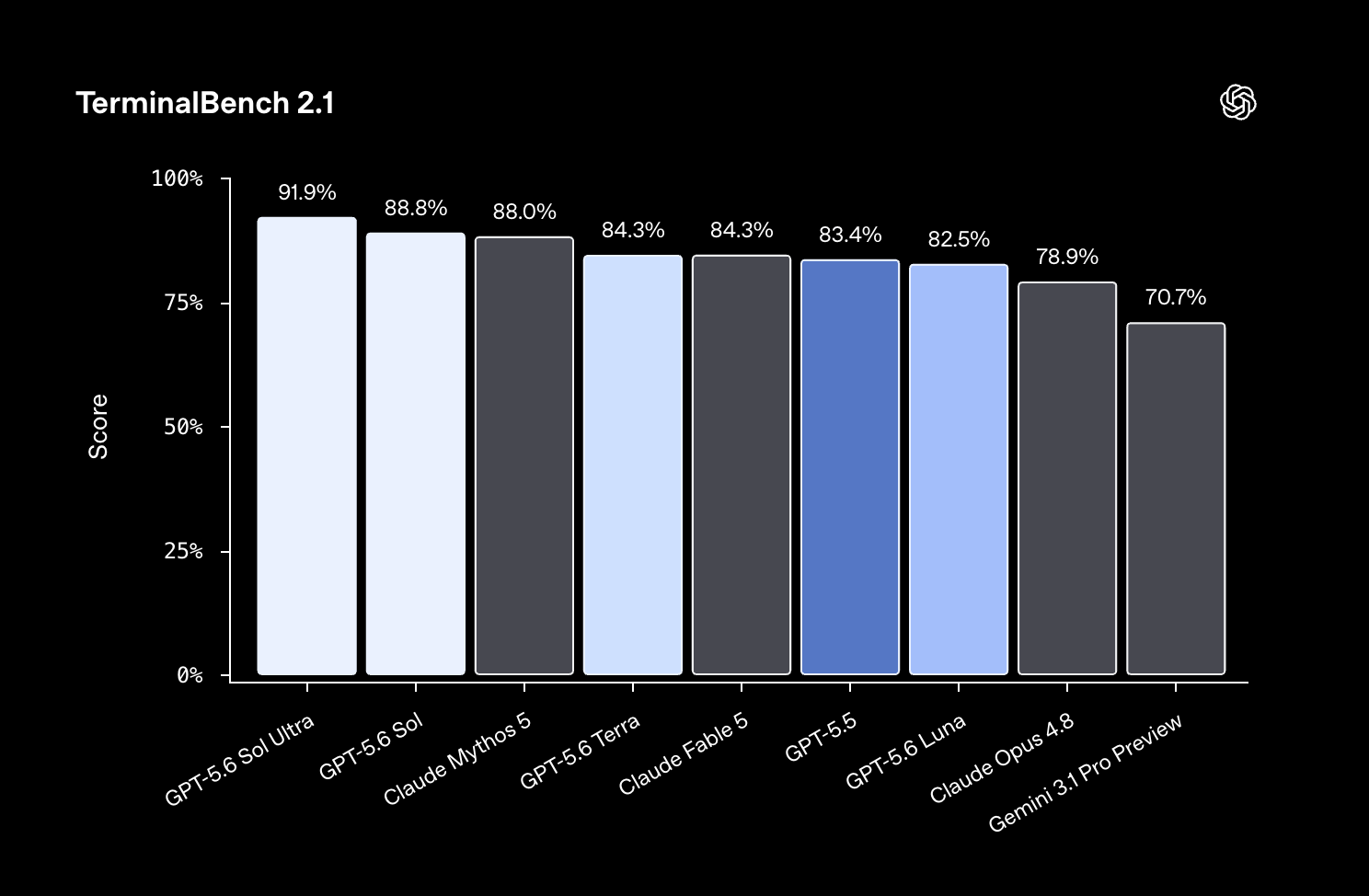
ومن المتوقع إن التكامل مع Cerebras خلال يوليو يرفع السرعة إلى 750 توكن في الثانية. ورغم إن سعره مماثل لـ GPT-5.5، تحسين كفاءة استهلاك التوكنز ممكن يقلل تكلفة تنفيذ المهام الفعلية بشكل ملحوظ.
قدرات سيبرانية أقوى مع ضوابط حماية أشد
الأهم إن النماذج الثلاثة الجديدة OpenAI صنفتها High Cybersecurity Risk. وده معناه إن أقوى النماذج المتاحة حاليًا، مثل Anthropic Fable 5 وMythos 5، بالإضافة إلى Sol وTerra وLuna من OpenAI، مش هتكون متاحة لعامة المستخدمين قبل مراجعات الأمن السيبراني الحكومية الأمريكية.فالسؤال دلوقتي مبقاش: مين عنده أفضل نموذج؟ لكنه بقى: أي نموذج مسموح لنا فعلًا نستخدمه؟
تم تطوير GPT-5.6 Sol وTerra وLuna مع أقوى إجراءات حماية طبقتها الشركة حتى الآن، بحيث تتناسب ال safeguards مع مستوى قدرات كل نموذج. الهدف هو أن تظل الحماية فعّالة أمام محاولات إساءة الاستخدام الواقعية، من غير ما تعطل الاستخدامات المشروعة مثل مراجعة الكود، البحث عن الثغرات، تطوير التحديثات الأمنية، الـdebugging، التعليم الأمني، والاختبارات الدفاعية.
النموذج GPT-5.6 Sol أفضل في مساعدة فرق الأمن على اكتشاف الثغرات وإصلاحها، لكنه لا يستطيع بشكل موثوق تنفيذ هجوم سيبراني كامل من البداية للنهاية. في اختبارات على Chromium وFirefox، قدر يحدد bugs وعناصر أساسية قد تدخل في بناء exploit، لكنه لم ينجح بشكل مستقل في إنتاج exploit كامل وفعّال ضمن ظروف الاختبار.
النموذج لا يتجاوز مستوى “Cyber Critical” حسب إطار التقييم الخاص بالشركة، لكن بسبب تطور قدراته بشكل ملحوظ واحتمال دمجه مع أدوات أخرى. الفكرة هي زيادة فائدته للمطورين وفرق الـdefensive security، مع جعل الاستخدام الهجومي المحظور أصعب وأقل قابلية للتنفيذ وأسهل في الاكتشاف.
اللي يهمنا كمبرمجين
هل أرقام ال Benchmarks فعلاً مفيدة؟
قراءة أخبار ال Models الجديدة من الشركات وأرقام ال Benchmark المبهرة دايمًا محتاجين ناخدها بإن عليها رشة ملح من المبالغة عشان التسويق.
بالفعل أرقام الـbenchmarking بتديك إشارة مفيدة، لكن نادرًا ما تكون حكمًا نهائيًا على جودة الموديل في شغلك. اعتبرها مؤشر اتجاه وليس ضمان أداء.
السبب إن كل Benchmark بيقيس شريحة ضيقة من القدرات تحت ظروف ثابتة: prompt محدد، بيانات تقييم معينة، أدوات محددة، وعدد محاولات أو budget معين. بينما شغلك الحقيقي فيه codebase خاص، conventions داخل الفريق، dependencies، أخطاء غير متوقعة، صلاحيات، واحتياج لفهم سياق طويل. موديل متفوق بـ3% في benchmark ممكن ما يفرقش معاك إطلاقًا، وموديل أقل في الرقم لكنه أسرع وأرخص وأكثر ثباتًا قد يكون أفضل في الإنتاج.
بنركّز كمان على نوع الـbenchmark نفسه. Benchmark مثل TerminalBench بيقيس قدرة الـagent على تنفيذ مهام في terminal، وبالتالي أقرب لسيناريوهات مثل تصليح bug، تشغيل tests، التعامل مع Git، أو تعديل ملفات متعددة. لكنه لا يثبت بالضرورة أن الموديل هيكتب architecture مناسب لمشروعك أو هيفهم business logic صح.
بالمقابل، benchmarks من نوع SWE-bench مفيدة أكثر في إصلاح issues داخل repositories حقيقية، لكنها برضه ممكن تتأثر بطريقة إعداد الـagent والأدوات المتاحة له.
الخطط البديلة ضرورية
زي ما وضحنا في أكثر من نشرة قبل كدا خطورة ال Vendor lock-in وبما إن الإتاحة العامة (طول الوقت) للنماذج دي غير مضمونة، ابنِ الـworkflow بحيث لا يرتبط بموديل واحد أو مورد واحد. استخدم abstraction layer للـLLM provider، وثبّت prompts و evaluation suite خاصة بمشروعك، واحتفظ بخيارات بديلة من OpenAI وAnthropic أو نماذج مفتوحة المصدر حسب متطلبات الخصوصية. ولو بتبني منتج معتمد على الذكاء الاصطناعي، متوعدش العملاء بميزة مبنية على موديل غير متاح للعامة. صمّم المنتج بحيث يعمل بمستوى جودة مقبول على الموديلات المتاحة حاليًا، ثم حسّنه تدريجيًا عند توفر موديلات أقوى.
Claude Fable 5 has Returned 🚀
تحت شعار “عاد إليكم من جديد!”
بعد 19 يوم من المنع، نموذج Claude Fable 5 رجع متاح عالميًا من خلال Claude.ai وClaude Code وClaude Cowork.

التعليق بدأ في يونيو بعد ما باحثين من Amazon وثّقوا طريقة Jailbreak خلت النموذج يقدر يحدد ثغرات في برمجيات مختلفة، وده أدى لتوجيه أمريكي خاص بضوابط التصدير فاضطرت الشركة تمنعه من كل المستخدمين وسحبته بالفعل.
خلال الفترة دي Anthropic درّبت Safety Classifier جديد يقدر يمنع الطريقة دي بشكل موثوق، وبعدها الحكومة رفعت القيود يوم 30 يونيو.
Anthropic رجّعت النموذج مع Classifiers جديدة هدفها منع إساءة الاستخدام في الأمن السيبراني. لكن خلال مرحلة الضبط وتقليل الـfalse positives، ممكن بعض من مهام البرمجة والـdebugging تتحول مؤقتًا إلى Opus 4.8 بدل Fable 5.
وفي نفس الوقت، نموذج Mythos 5 بيرجع بشكل محدود لمجموعة من المؤسسات الأمريكية ضمن برنامج Glasswing. بالنسبة للمطورين، رجوع Fable 5 إلى Claude Code يعتبر أهم حدث لمستخدمين Claude الفترة دي لأنه قبل المنع كان بالفعل سايب انطباع كويس عن كفاءته!
القصة دي كانت أزمة فعلية وخلت المجتمع كله قلقان لأن نموذج قوي للبرمجة في أكبر Code Agent اتسحب من السوق، وبعدها دخل في مفاوضات، واتضافت له طبقة حماية موجهة، ثم رجع تاني بإجراءات أمان أقوى من قبل.
هل هيكون دا التسلسل الطبيعي بعد كدا لكل ال Frontier AI Labs بأنها لازم تعدي علي فقرة مفاوضات مع الحكومة عشان تتأكد من عدم إساءة استخدام النماذج في الهجمات الأمنية؟ دا وارد جدًا لأننا شايفين دلوقتي OpenAI داخلة ب GPT-5.6 Sol في نفس العملية مع اعتراضها الشديد عليها.
الجدير بالذكر إن شركة Anthropic، بالتعاون مع Amazon وMicrosoft وGoogle، بتشتغل على معيار موحّد على مستوى الصناعة لتقييم مدى خطورة محاولات كسر حماية نماذج الذكاء الاصطناعي (AI jailbreaks).
المعيار ده هيعتمد على 4 عوامل أساسية: حجم الزيادة في قدرات النموذج مقارنة بسابقه، مدى اتساع القدرات الجديدة دي، سهولة تحويلها لاستخدام ضار أو هجومي، ومدى سهولة اكتشاف طريقة كسر الحماية من الأساس.
اللي يهمنا كمبرمجين
النموذج أصبح متاح ومستخدمين Claude Code في مجتمعنا العربي كتير فابعتولنا تقييماتكم علي استخدامه وهنضيفها للنشرة باذن الله!
النموذج بيوفر Context Window بتوصل إلى مليون توكن، ودي ميزة عملية كبيرة في الشغل داخل Codebases كبيرة أو Agentic Tasks طويلة؟
من الناحية المالية، سعره بالفعل عالي، يأتي Fable 5 بـ 10$/Input و50$/Output ودا ضعف سعر Opus 4.8 وضعف سعر GPT-5.5 تقريبًا على المدخلات بس استخدام ال Prompt Caching و ال Batch API بيقلل التكلفة للنص, على كل حال لازم ناخذ بالنا من الفواتير!
GLM-5.2 :The Open Source Finally in the Frontier 🔥
شركة Z.ai أطلقت نموذج GLM-5.2، وهو نموذج مفتوح الأوزان بحجم 744B Parameter وبيعتمد على بنية Mixture-of-Experts. النموذج بيدعم ContextWindow لحد مليون token، ومرخّص برخصة MIT.

حاليًا بيُقال إنه أقوى نموذج مفتوح الأوزان في اختبارات الأداء، وبيتفوق على GPT-5.5 في عدد من اختبارات هندسة البرمجيات، مع أسعار API أقل بكتير من النماذج المغلقة أو المملوكة.
لكن لازم نقرأ الأرقام دي بحذر: الـbenchmarks بتوضح اتجاه الأداء، لكنها مش ضمان إن النموذج هيكون الأفضل على مشروعك. التجربة الحقيقية بتعتمد على الـstack، حجم الـrepository، جودة الـtests، طريقة بناء الـagent، والـtools اللي بتسمح له يستخدمها.
التركيز الأساسي في GLM-5.2 هو إنه ينجز مهام هندسة برمجيات فعلية، مش مجرد يولّد snippets أو يشرح كود. المفروض يقدر يفهم المشكلة، يخطط للحل، يعدّل ملفات متعددة، يشغّل أدوات واختبارات، ويراجع النتيجة.
أهم تفاصيل النموذج
حقق أعلى نتيجة بين النماذج مفتوحة الأوزان على مؤشر Artificial Analysis Intelligence Index.
بيستخدم رخصة MIT، وده معناه إنك تقدر تستخدمه تجاريًا من غير قيود كبيرة، تستضيفه محليًا، وتعمل له fine-tuning من غير قيود استخدام أو حدود جغرافية. ده بيخليه اختيار مناسب لو عندك متطلبات خصوصية، أو بيانات حساسة، أو عايز تقلل اعتمادك على APIs مغلقة.
تشغيله محليًا يحتاج على الأقل 256GB RAM للنسخ المضغوطة أو الـquantized، بالإضافة إلى 24GB VRAM لو هتستخدم MoE offloading. فعمليًا النموذج مناسب أكثر لسيرفرات قوية، cloud instances، أو فرق عندها بنية تحتية مخصصة، مش لجهاز مطور عادي.
حاليًا النموذج لا يدعم الرؤية، يعني لا يقدر يفهم أو يحلل الصور اللي بتبعتهاله بالتالي، لو شغلك بيعتمد على تحليل واجهات من صور، debugging من screenshots، أو multimodal workflows، هتحتاج موديل تاني أو pipeline إضافي.
الفجوة بين النماذج مفتوحة الأوزان والنماذج المملوكة كانت تاريخيًا بتتقاس بالشهور، لكن GLM-5.2 بيشير إن الفجوة في مهام البرمجة ممكن تكون قربت جدًا من الصفر.
النقطة اللي لسه محتاجة تقييم هي كفاءة الـreasoning: النموذج بيستهلك في المتوسط حوالي 43 ألف output token لكل مهمة، وده يقارب 3 أضعاف استهلاك GPT-5.5. عمليًا، ده ممكن يخلي تنفيذ المهام أبطأ وأكثر تكلفة من ناحية وقت المعالجة داخل production pipelines، حتى لو سعر الـAPI نفسه
الكفاءة والتكلفة
رغم إن النموذج مفتوح الأوزان وأسعار الـAPI بتاعته أقل من نماذج مغلقة كتير، فيه نقطة مهمة تخص كفاءة الـreasoning. النموذج بيستخدم في المتوسط حوالي 43 ألف output token لكل مهمة، وده قريب من 3 أضعاف استهلاك GPT-5.5 حسب المقال. عمليًا، ده ممكن يزود وقت تنفيذ المهمة ويأثر على throughput في الـproduction pipelines، حتى لو تكلفة الـtoken نفسها أقل.
بمعنى آخر: سعر الـAPI الأقل مش بالضرورة معناه إن تكلفة المهمة النهائية أقل. لو النموذج بيحتاج tokens أكتر ووقت أطول علشان يوصل لنفس النتيجة، لازم تقارن على أساس تكلفة المهمة الناجحة، مش سعر المليون token فقط.
الخلاصة للمبرمجين
GLM-5.2 بيقرب جدًا من مستوى النماذج المغلقة في مهام البرمجة، مع ميزة كبيرة وهي حرية التشغيل والتعديل تحت رخصة MIT. ده يخليه خيار قوي للفرق اللي عايزة self-hosting، خصوصية أعلى، وتحكم كامل في الـdeployment.
لكن قبل ما تعتمد عليه في الإنتاج، اختبره على مهام من مشروعك: bugs، refactoring، كتابة tests، code review، وتشغيل الـagents داخل الـCI. قارن بينه وبين البدائل في نسبة نجاح الـtests، وقت التنفيذ، عدد الـtokens، وعدد التدخلات البشرية المطلوبة. النموذج الأفضل مش بالضرورة الأعلى في الـbenchmark، لكنه اللي ينجز شغلك بدقة وبأقل تكلفة تشغيل فعلية.

بفضل الله أصبح متاح حالياَ دعمنا من خلال الرعاة والشراكات وفعلنا الـ Sponsorship, بنرحب بجميع الشراكات مع المؤسسات والشركات وأصحاب الأعمال لبناء مجتمع عربي يشجع على القراءة والتعلم ومشاركة التجارب والخبرات العملية في هندسة البرمجيات.
دورك كشريك أو راعي هيكون محوري في دعم المحتوى وتوسيع نطاق تأثيره. فانضم لرحلتنا وكن جزءًا من صناعة مستقبل التكنولوجيا في المنطقة 🚀

تقدروا تشوفوا التفاصيل كاملة من هنا والـ Analytics بتاعتنا من خلال اقرأ-تِك والنشرة الأسبوعية 👇

رؤيتنا هي إثراء المحتوى التقني العربي وجعل التعلم من خلال القراءة أمتع، وذلك من خلال إثراء المحتوى التقني باللغة العربية وتشجيع المبرمجين على القراءة بلغتهم الأم والتفكير أيضًا بها.
لذلك اتحنا الفرصة أمام الجميع للمساهمة ومساعدتنا في نشر واثراء المحتوى التقني باللغة العربية, من خلال كتابة المقالات التقنية في مختلف مجالات هندسة البرمجيات.
وجب التنويه أنه لن يتم نشر كافة الأعمال التي تصل إلينا، وإنما سيتم الانتقاء منها ما يحقق هدفنا بإثراء المحتوى التقني العربي، ولذلك قد تُطلب بعض التعديلات من الكاتب قبل النشر.
لمعرفة المزيد بخصوص :
💬 المعايير العامة لكتابة ونشر المقالات
⚡️ كيفية الإرسال
🔥 التزامات اقرأ-تِك تجاه الكتاب
يمكنكم قراءة كافة التفاصيل من هنا 👇
